
원본 논문 링크 : https://arxiv.org/abs/2112.10752
High-Resolution Image Synthesis with Latent Diffusion Models
By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism t
arxiv.org
0. Abstract
이미지 형성 과정을 순차적으로 적용하는 denoising autoencoders (Denoising Autoencoder)의 확산 모델을 사용하여 이미지 데이터와 그 이상의 분야에서 최첨단 합성 결과를 달성한다. 확산 모델은 이미지 생성 과정을 통제할 수 있는 안내 메커니즘을 제공하지만, 일반적으로 픽셀 공간에서 직접 작동하기 때문에 강력한 DM의 최적화는 수백 개의 GPU 일을 소비하고 순차적 평가로 인해 추론하는데 비용이 많이 든다. 제한된 계산 자원으로 DM 학습을 가능하게 하면서 그들의 품질과 유연성을 유지하기 위해 우리는 그들을 강력한 사전 훈련된 autoencoder의 잠재 공간에 적용한다.
| 초록에서는 확산 모델(Diffusion Models, DMs)의 특성과 그들이 직면하는 계산적 제약에 대해 설명합니다. 여기서 말하는 '확산 모델'은 이미지 생성 과정에서 노이즈를 점진적으로 제거해가며 최종 이미지를 생성하는 일련의 디노이징 오토인코더를 기반으로 한 생성 모델입니다. 이미지 생성 과정의 통제: 확산 모델은 생성 과정을 안내하고 통제할 수 있는 메커니즘을 가지고 있습니다. 이는 생성하고자 하는 이미지에 특정 지침을 적용하여 원하는 결과를 얻을 수 있음을 의미합니다. 예를 들어, 텍스트 설명을 기반으로 이미지를 생성하거나 특정 스타일을 모방하는 등의 작업이 가능합니다. (1) 픽셀 공간에서의 작동: DM은 픽셀 수준에서 작동합니다. 즉, 모델은 이미지의 각 픽셀에 대해 연산을 수행하며, 이는 고해상도 이미지의 경우 매우 계산 집약적일 수 있습니다. (2) 강력한 DM의 최적화: 최적화된 DM을 통해 높은 품질의 이미지 생성을 달성하기 위해 많은 양의 계산 자원이 필요합니다. '수백 개의 GPU 일'이라는 표현은 이러한 모델을 훈련시키는 데 필요한 계산량이 막대하다는 것을 나타냅니다. (3) 순차적 평가와 추론 비용: DM의 추론 과정은 순차적입니다. 즉, 이미지 생성을 완료하기 위해 여러 단계를 거쳐 각 단계마다 모델을 실행해야 합니다. 이는 단일 이미지를 생성하는 데도 상당한 시간과 계산 자원을 요구할 수 있습니다. 이러한 설명은 확산 모델이 고해상도 이미지 생성에 있어 탁월한 결과를 낼 수 있지만, 높은 계산 비용과 시간이라는 상당한 제약이 따른다는 것을 보여줍니다. 이는 특히 자원이 제한된 상황에서 더욱 도전적인 문제가 될 수 있으며, 이러한 계산 비용을 줄이기 위한 연구가 활발히 진행 중입니다. |
1. Introduction
이미지 합성은 컴퓨터 비전 분야 중 최근 가장 눈부신 발전을 이루었지만 가장 많은 계산 요구 사항 중 하나이다.
고해상도 복잡한 자연 장면의 합성은 현재 수십억 개의 매개변수를 포함하는 확률 기반 모델의 확대에 의해 지배된다.
( Image synthesis is one of the computer vision fields with the most spectacular recent development, but also among those with the greatest computational demands. Especially high-resolution synthesis of complex, natural scenes is presently dominated by scaling up likelihood-based models, potentially containing billions of parameters in autoregressive (AR) transformers.)
| Autoregressive Model : 오리지날 트랜스포머 모델의 decoder를 사용하며, 이전 모든 토큰들을에 대해 다음 토큰을 예측하는 방식으로 대해 사전 학습 된다. 트랜스포머 어텐션에서 다음 문장을 예측할때, 전체 문장의 윗부분을 마스킹 처리하여, 어텐션 헤드가 예측하고자 하는 다음 토큰 이전까지만 볼 수 있도록 한다. 대표적인 모델로는 GPT 모델이 있으며, 대표적인 예로는 텍스트 생성 태스크가 있다. |

위 이미지는 확산 모델의 성능을 보여주는 Figure 1입니다. 이 그림은 확산 모델이 공간 데이터에 대한 우수한 유도 편향을 제공하기 때문에 관련 생성 모델의 잠재 공간에서 무거운 공간 다운샘플링을 필요로 하지 않음을 보여줍니다. 그러나 적절한 오토인코딩 모델을 통해 데이터의 차원을 크게 줄일 수 있습니다
| <평가지표 종류 :> - 1. PSNR (Peak Signal-to-noise ratio): PSNR은 영상 화질 손실양을 평가하기 위해 사용되는 지표입니다. 이미지 저장, 전송, 압축, 영상 처리 등에서 영상 화질이 바뀌었을 때 사용됩니다. - 2. 프레쳇 인셉션 거리(FID) : 이 메트릭은 실제 이미지와 생성된 이미지 간의 특징 거리 측정에 가장 널리 사용되는 매트릭 중 하나입니다. 프레쳇 거리Frechet Distance는 곡선을 따라는 점들(points)의 위치와 순서를 고려한 곡선 간의 유사성을 측정하는 방법입니다. 이는 두 분포 사이의 거리를 측정하는 데에도 사용됩니다. |
그림에서 세 가지 다른 접근법의 결과를 비교하고 있습니다:
1. Ours (f = 4): 이 연구에서 제안된 모델로, 공간 다운샘플링 요소(f)가 4인 경우를 나타냅니다. 이 모델은 PSNR이 27.4, Reconstruction FID가 0.58로 평가되었습니다. 이 수치들은 이미지 재구성의 정확성과 품질을 나타내며, 여기서 높은 PSNR 값과 낮은 FID 점수는 우수한 이미지 품질을 의미합니다.
2. DALL-E (f = 8): 또 다른 모델로, 공간 다운샘플링 요소가 8입니다. 이 모델은 PSNR이 22.8, Reconstruction FID가 32.01로, 제안된 모델에 비해 낮은 성능을 보입니다.
| DALL-E: OpenAI가 개발한 이미지 생성 모델이다 .VQ-VAE (Vector Quantized Variational AutoEncoder) 기반의 변형을 사용합니다. DALL-E는 VQ-VAE를 사용하여 이미지를 이산적인 잠재 공간으로 변환하고, 이후 변형된 GPT (Generative Pre-trained Transformer) 아키텍처를 사용하여 이 잠재 공간에서 이미지를 생성합니다. |
3. VQGAN (f = 16): 공간 다운샘플링 요소가 16인 또 다른 접근법으로, PSNR은 19.9, Reconstruction FID는 4.98로 나타났습니다. 이것은 다른 두 모델과 비교하여 낮은 해상도에서 이미지를 재구성할 때 더 큰 세부 정보의 손실을 나타냅니다.
| VQGAN : VQGAN (Vector Quantized Generative Adversarial Network)은 컴퓨터 비전과 딥러닝 분야에서 사용되는 고급 이미지 생성 모델입니다. 이 모델은 GAN (Generative Adversarial Networks)과 VQ-VAE (Vector Quantized Variational AutoEncoders)의 개념을 결합하여 만들어졌습니다. VQGAN은 이미지 생성에 있어서 높은 품질과 세부적인 표현력을 제공합니다. VQGAN의 주요 구성요소 VQ-VAE (Vector Quantized Variational AutoEncoders): 변형 오토인코더: 이미지를 효율적으로 압축하고 복원하는 데 사용됩니다. 벡터 양자화: 연속적인 잠재 공간을 이산적인 표현으로 변환하여 이미지의 특징을 보다 효과적으로 인코딩합니다. GAN (Generative Adversarial Networks): 생성자(Generator): 새로운 이미지를 생성합니다. 판별자(Discriminator): 진짜와 가짜 이미지를 구별하며, 생성자를 향상시키는 데 사용됩니다. |
이러한 수치들은 각 모델이 DIV2K 검증 세트의 512² 픽셀 이미지에서 얼마나 잘 재구성하는지를 보여줍니다. 다운샘플링 요소(f)는 이미지의 공간 해상도를 줄이는 데 사용되는 비율을 나타내며, f 값이 클수록 더 많은 다운샘플링이 발생하고, 이는 잠재적으로 더 많은 이미지 세부 정보의 손실을 의미합니다.
이 그림은 확산 모델, 특히 이 논문에서 제안한 저차원 잠재 공간에서의 확산 모델이 고해상도 이미지 합성에서 얼마나 효과적일 수 있는지를 시각적으로 보여주는 강력한 예입니다. 여기서 'ours'는 적은 다운샘플링으로도 이미지의 높은 품질을 유지하는 것을 보여주며, 이는 고해상도 이미지 합성에 있어서 중요한 이점입니다.
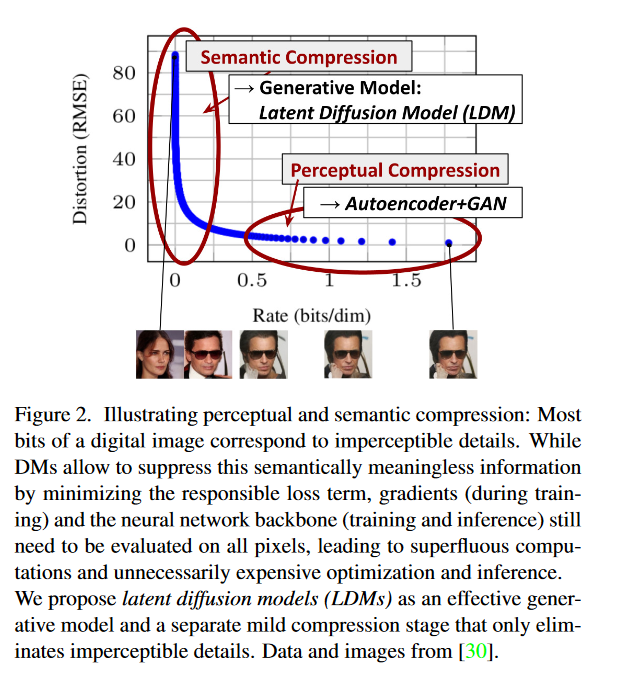
위 이미지는 Figure 2로, 지각적(Perceptual) 및 의미론적(Semantic) 압축을 시각적으로 보여주고 있습니다.
그래프는 두 가지 차원에서 압축을 나타냅니다. 압축률(Rate, bits/dim)과 왜곡(Distortion, RMSE)입니다.
- 압축률(Rate): 이미지를 압축할 때 얼마나 많은 비트를 사용하는지를 나타내며, 단위는 비트 당 차원(bits/dim)으로 표시됩니다. 압축률이 낮을수록 더 적은 비트를 사용하여 데이터를 저장하고 전송합니다.
- 왜곡(Distortion): 원본 이미지에서 압축된 이미지로의 변화에서 발생하는 품질 저하를 나타내는 지표로, 여기서는 RMSE(Root Mean Square Error)를 사용하여 측정합니다. RMSE 값이 낮을수록 원본에 더 가까운 이미지 품질을 의미합니다.
그래프는 두 가지 중요한 부분을 강조합니다.
1. Perceptual Compression (지각적 압축): 이 영역은 오토인코더와 GAN(Generative Adversarial Networks)을 사용하여 구현된 압축 모델의 성능을 보여줍니다. 이러한 모델은 일반적으로 낮은 왜곡을 유지하면서도 비교적 낮은 비트율에서 좋은 성능을 보여줍니다.
2. Semantic Compression (의미론적 압축): 여기서 제안하는 Latent Diffusion Model (LDM)이 위치한 영역입니다. LDM은 의미론적으로 무의미한 정보를 억제하고 압축 과정에서 그 책임지는 손실 항목을 최소화함으로써 더 낮은 비율의 비트에서도 낮은 왜곡을 달성하는 것을 목표로 합니다.
그래프 아래에 있는 이미지들은 LDM을 사용하여 압축 및 재구성한 이미지의 예를 보여줍니다. 이러한 이미지는 LDM이 어떻게 효과적인 압축을 달성하면서도 눈에 띄지 않는 세부 사항을 제거하여 이미지 품질을 유지하는지를 시각적으로 보여줍니다.
논문의 저자들은 LDM이 기존의 오토인코더와 GAN에 비해 훨씬 효율적인 압축을 제공하며, 동시에 훈련 및 추론 단계에서 필요 이상의 계산을 줄일 수 있음을 주장합니다. 이러한 특성은 LDM을 효율적인 생성 모델로 만들고, 불필요한 세부 정보를 제거하는 압축 단계와 결합하여 고품질의 이미지를 생성할 수 있는 능력을 제공합니다.
2. Related work
이미지의 고차원적 특성은 생성 모델링에 독특한 도전을 제시한다.
최근 확산 확률 모델은 밀도 추정 및 샘플 품질에서 최첨단 결과를 달성했다.
(내용 짧음)
3. Method
고해상도 이미지 합성을 위한 확산 모델 훈련의 계산 요구 사항을 낮추기 위해, 우리는 인식에 중요하지 않은 세부 사항을 무시하게 하는 확산 모델을 제안한다
3.1. Perceptual Image Compression
우리의 지각적 압축 모델은 이전 연구에 기반하고 있으며, perceptual loss와 patch-based adversarial objective의 조합으로 훈련된 autoencoder로 구성된다. 이 모델은 이전 연구를 바탕으로 하며, perceptual loss와 patch-based adversarial objective의 조합으로 훈련된 autoencoder로 구성됩니다. 이러한 접근 방식은 이미지의 지각적 특징을 유지하면서도 bluriness를 방지합니다. 주어진 이미지 x에 대해 encoder E는 x를 잠재 표현 z로 인코딩하고, decoder D는 이를 다시 이미지로 재구성합니다. Encoder는 이미지를 다운샘플링하며, 다양한 다운샘플링 요소를 실험합니다. 또한, 높은 변이를 가진 잠재 공간을 피하기 위해 두 가지 정규화 방식을 사용합니다: 하나는 VAE와 유사한 KL-penalty, 다른 하나는 디코더 내의 벡터 양자화 레이어를 사용하는 VQ-reg입니다
| Perceptual loss : 지각손실 오토인코더: 오토인코더는 레이블이 없는 데이터의 효율적인 표현(인코딩)을 학습하기 위해 사용되는 신경망 유형입니다. 주로 차원 축소를 위해 사용되며, 두 주요 부분으로 구성됩니다: 인코더는 입력 데이터를 압축하고, 디코더는 압축된 표현으로부터 입력 데이터를 재구성합니다. 전통적인 손실 함수: 일반적으로 오토인코더는 입력과 재구성된 출력 간의 차이를 직접 픽셀 공간에서 측정하는 평균 제곱 오차(MSE)와 같은 손실 함수를 사용하여 훈련됩니다. 이 접근 방식은 간단하지만, 때때로 흐릿하거나 덜 세부적인 재구성으로 이어질 수 있습니다. 지각 손실: 지각 손실은 이러한 문제를 해결하기 위해 도입되었습니다. 지각 손실은 입력과 출력 이미지를 픽셀 공간에서 직접 비교하는 대신, 일반적으로 사전 훈련된 컨볼루션 신경망(VGG나 ResNet 같은)에서 추출된 특징 공간에서 차이를 측정합니다. 작동 방식: 지각 손실의 아이디어는 입력과 출력 이미지의 정확한 픽셀 값을 비교하는 대신, 두 이미지의 고차원 특징(예: 질감, 가장자리, 일반 패턴)이 얼마나 유사한지를 비교하는 것입니다. 이는 입력 및 출력 이미지를 별도의 특징 추출 네트워크(일반적으로 사전 훈련된 분류 모델의 일부)를 통과시키고 그들의 고차원 표현 간의 손실을 계산함으로써 이루어집니다. 장점: 지각 손실을 사용함으로써 오토인코더는 이미지의 "느낌"이나 "내용"을 유지하는 데 집중하도록 학습하며, 이는 시각적으로 더 만족스러운 결과를 가져옵니다. 스타일 전송, 초고해상도, 사진 향상과 같은 작업에서 픽셀 수준의 정확성보다 이미지의 "느낌" 또는 "내용"을 유지하는 것이 더 중요할 때 특히 유용합니다. 딥러닝에서의 응용: 딥러닝에서 지각 손실은 다양한 생성 모델에서 출력물의 시각적 품질을 향상시키는 핵심 기술입니다. 이는 인간의 지각 품질이 최종 벤치마크인 작업에서 전통적인 손실 함수를 넘어서는 중요한 발전입니다. |
| Patch-based Adversarial Objective : GANs의 기본 원리: GANs는 생성자(Generator)와 판별자(Discriminator)라는 두 개의 신경망을 사용합니다. 생성자는 진짜처럼 보이는 데이터를 생성하려고 하며, 판별자는 생성된 데이터와 실제 데이터를 구별하려고 합니다. 전통적인 적대적 목표: 전통적인 GAN에서, 판별자는 전체 이미지를 기반으로 진짜와 가짜를 판별합니다. 즉, 판별자는 전체 이미지가 진짜인지 생성된 것인지를 결정합니다. 패치 기반 적대적 목표: 이 개념은 판별자가 전체 이미지 대신 이미지의 작은 '패치'들을 기반으로 진위를 판별하도록 합니다. 즉, 판별자는 이미지의 각 작은 부분이 진짜인지 가짜인지를 개별적으로 평가합니다. 작동 방식: 생성된 이미지는 패치로 나누어지고, 판별자는 이 각각의 패치가 실제 데이터의 패치와 얼마나 유사한지를 평가합니다. 이렇게 함으로써, 판별자는 더 세부적인 수준에서 이미지의 진위를 판별할 수 있게 됩니다. 장점: 이 접근법은 생성자가 더 세부적이고 현실적인 텍스처와 패턴을 생성하도록 강제합니다. 전체 이미지 수준보다 더 작은 수준에서의 진위 평가는 생성된 이미지의 품질을 향상시키는 데 도움이 됩니다. 응용: 패치 기반 적대적 목표는 특히 이미지 슈퍼-레졸루션, 스타일 전환, 텍스처 합성 등과 같은 영역에서 유용합니다. 이런 작업에서는 이미지의 세부적인 질감과 패턴이 중요하기 때문에, 패치 기반 접근법이 더욱 효과적일 수 있습니다. 요약하자면, 패치 기반 적대적 목표는 판별자가 이미지의 작은 부분들을 개별적으로 평가함으로써 생성자가 더 세밀하고 현실적인 이미지를 생성하도록 하는 GANs의 한 방법입니다. 이는 전체 이미지를 평가하는 전통적인 방법보다 더 상세한 질감과 패턴을 생성하는데 도움이 됩니다. |
3.2. Latent Diffusion Models
잠재 확산 모델(LDM)은 점차적으로 noise를 제거하여 데이터 분포 p(x)를 학습하는 확률 모델입니다. 이 모델은 T 길이의 고정된 Markov Chain의 역과정을 학습하는 것과 동일합니다. 이미지 합성을 위한 이 모델들은 p(x)의 재가중 변형된 하한을 사용합니다. 이 모델들은 일련의 denoising autoencoders로 해석될 수 있으며, 입력된 노이즈가 있는 이미지 xt를 denoised 버전으로 예측하는 것이 목표입니다. 훈련된 지각적 압축 모델을 통해 고주파수 세부사항이 추상화된 효율적인 저차원 잠재 공간에 접근할 수 있습니다. 이는 고차원 픽셀 공간보다 likelihood 기반 생성 모델에 더 적합합니다
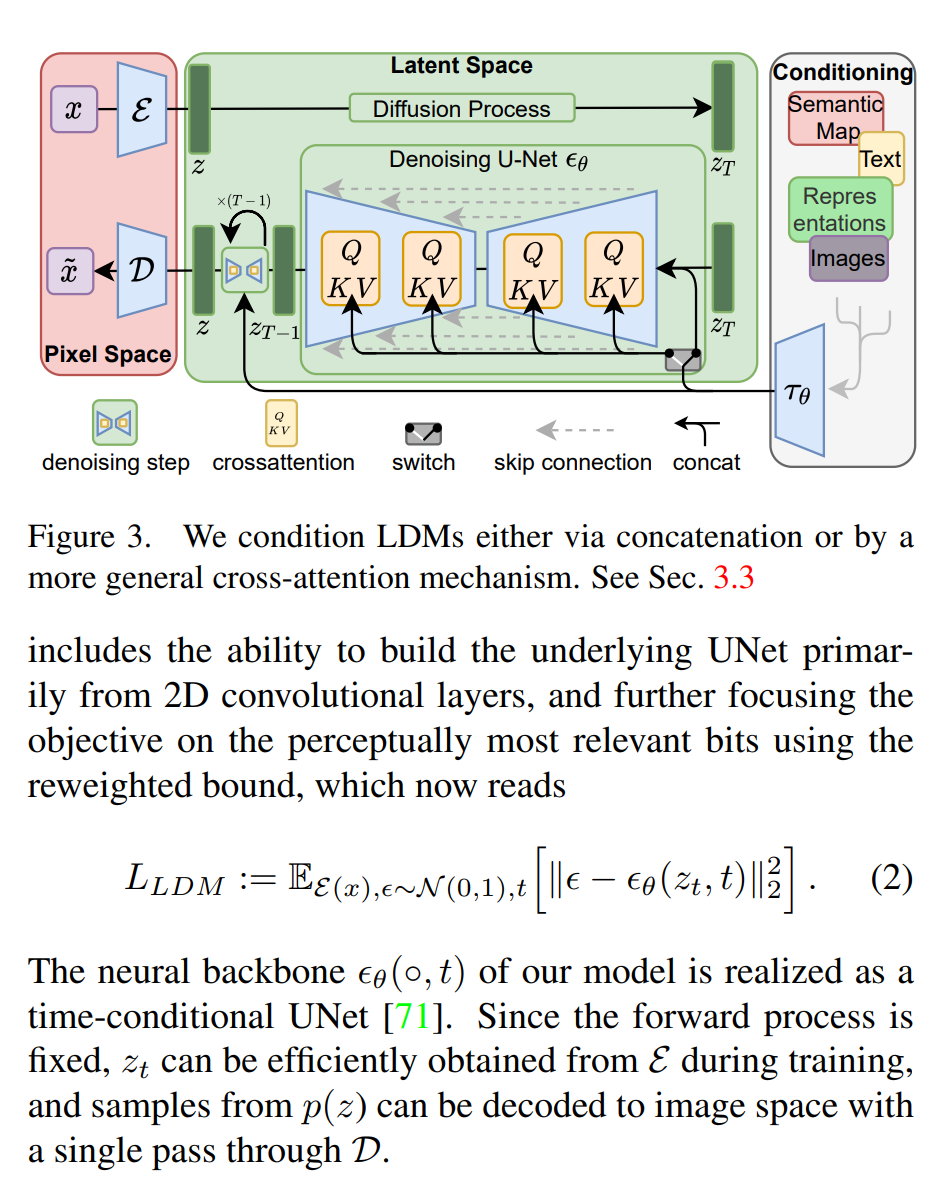
그림 3은 잠재 확산 모델(Latent Diffusion Models, LDMs)의 조건부 메커니즘을 설명하는 다이어그램입니다. 이 그림은 LDM의 전반적인 아키텍처와 데이터 흐름을 시각적으로 보여줍니다. 여기서 LDM은 픽셀 공간에서 잠재 공간으로 이미지를 변환하는 데 사용되는 인코더 E와 잠재 공간에서 픽셀 공간으로 이미지를 재구성하는 데 사용되는 디코더 D로 구성되어 있습니다.
- LDM 아키텍처:
인코더 E: 원본 이미지 x를 입력으로 받아 잠재 표현 z로 변환합니다.
디코더 D: 잠재 표현 z를 받아 원본 이미지와 유사한 이미지 x^ 을 출력합니다.
확산 과정: 잠재 공간에서 발생하는 여러 디노이징 단계를 거칩니다. 이 과정은 일련의 디노이징 U-Net θ로 구성되며, 각 단계에서 이미지의 잠재 표현을 점차적으로 정제합니다.
조건부 메커니즘: LDM은 결합(concatenation) 또는 보다 일반적인 크로스 어텐션 메커니즘을 통해 조건을 부여받을 수 있습니다. 이를 통해 텍스트, 의미론적 지도(semantic maps), 이미지 등과 같은 다양한 형태의 데이터를 모델에 통합할 수 있습니다.
- LDM 손실 함수:
수식에서 L_LDM 은 LDM의 손실 함수를 나타냅니다. 이는 디노이징 단계에서 예측된 이미지와 실제 이미지 사이의 평균 제곱 오차(Mean Squared Error, MSE)를 최소화하는 것을 목표로 합니다. 수식은 다음과 같습니다:
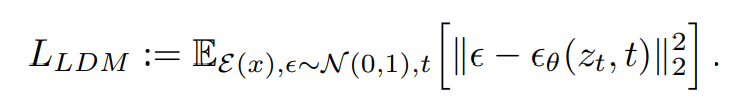
이 수식은 ϵ이라는 노이즈 변수를 기반으로 생성된 x_t 라는 중간 이미지와, 모델 θ에 의해 예측된 노이즈 ϵ_θ(z_t, t) 사이의 거리를 계산합니다. 여기서 E는 기대값을,
N(0,1)은 표준 정규 분포를 나타냅니다. 손실 함수는 모델이 실제 데이터 분포를 정확하게 학습하여 높은 품질의 이미지를 생성할 수 있도록 돕습니다.
이 다이어그램과 수식은 LDM이 어떻게 이미지 생성 과정을 최적화하고 다양한 형태의 데이터에 대한 생성을 가능하게 하는지를 보여줍니다. 이러한 메커니즘은 특히 고해상도 이미지 생성과 관련된 작업에 있어 계산 비용을 크게 절감할 수 있는 효과적인 방법입니다.
3.3. Conditioning Mechanisms
이 섹션에서는 확산 모델을 조건부 생성 모델로 변환하는 방법을 다룹니다. 이를 위해 UNet의 기본 구조에 cross-attention 메커니즘을 추가합니다. 이 접근 방식은 다양한 입력 형식(예: 텍스트, 의미적 지도)에 대해 모델을 조절할 수 있게 해줍니다. 예를 들어, 언어 프롬프트에 대해 훈련된 1.45B 매개변수의 KL-regularized LDM은 복잡한 사용자 정의 텍스트 프롬프트에 잘 일반화됩니다. 이 모델은 MS-COCO 데이터셋에서 AR 및 GAN 기반 방법보다 우수한 성능을 보여줍니다
| * KL-regularized LDM은 잠재 확산 모델(Latent Diffusion Model)의 한 형태로, 훈련 과정에서 Kullback-Leibler (KL) 발산을 기반으로 하는 정규화 항을 포함합니다. 이 모델은 인코더가 주어진 데이터 x에 대해 생성한 잠재 변수 z의 분포가 표준 정규 분포와 유사하도록 유도하는데, 이는 표준 변분 오토인코더(Variational Autoencoder, VAE)에서 사용되는 방식과 유사합니다. 이 KL 정규화는 모델이 생성한 잠재 공간의 분포를 제어 가능하고 예측 가능한 범위 내로 유지하도록 돕습니다. 이는 새로운 샘플을 생성할 때 원본 데이터 분포와의 일관성과 고품질을 유지하는 데 도움이 됩니다. KL 정규화 항은 매우 작은 가중치(약 10^-6 의 인자)로 적용되어, 잠재 공간이 정규 분포를 따르도록 격려하지만, 너무 엄격하게 강제하지는 않습니다. 이는 다양성과 생성된 데이터의 질을 유지하면서도 안정적인 훈련 과정을 제공하는 데 도움을 줍니다 |
| "AR"은 "Autoregressive"의 약자입니다. Autoregressive 모델은 다음 데이터 포인트를 예측하기 위해 이전의 데이터 포인트들을 사용하는 시퀀스 모델링에 사용됩니다. 이미지 생성의 맥락에서 AR 모델은 픽셀 또는 이미지 패치의 시퀀스를 생성할 때 이전 픽셀들의 값에 기초하여 다음 픽셀의 값을 예측합니다. 가장 잘 알려진 AR 모델 중 하나는 PixelRNN이나 PixelCNN과 같은 모델로, 이미지의 각 픽셀을 순차적으로 생성합니다. 이러한 AR 모델은 정확한 확률 분포 추정을 가능하게 하고 강력한 성능을 제공할 수 있지만, 픽셀 단위로 순차적인 처리를 해야 하기 때문에 종종 계산이 매우 복잡하고 시간이 많이 소요됩니다. 이는 고해상도 이미지 생성과 같은 경우에 특히 그렇습니다. 따라서, 논문에서 언급하는 "AR 및 GAN 기반 방법보다 우수한 성능"이라는 말은 잠재 확산 모델(Latent Diffusion Models)이 이러한 제한점을 극복하고 더 나은 성능을 제공할 수 있음을 시사합니다. |
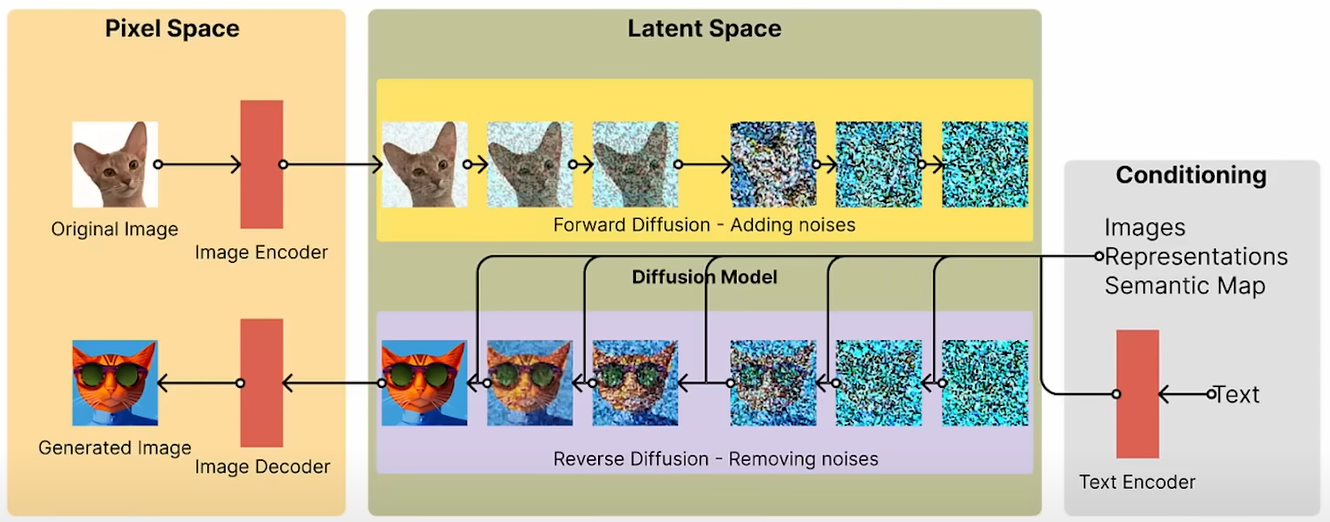
| Forward Diffusion으로 training을 해놓으면, 나중에는 특정한 이미지의 커맨드가 나오면 그걸 통해서 역으로 이러한 노이즈로부터 이미지를 생성해냄. 역 Diffusion을 통해서 고해상도, 고퀄리티의 이미지를 생성해낼 수 있는 것임. ▶여기서 확장된 모델이 약 4배 정도 큰 Model 인 SDXL이다. |
4. Experiments

4.1. On Perceptual Compression Tradeoffs
다양한 다운샘플링 요소를 가진 LDM의 성능을 분석합니다. 작은 다운샘플링 요소는 훈련 진행 속도가 느리지만, 너무 큰 요소는 초기 단계 이후에 품질이 정체됩니다. LDM-4와 LDM-8은 효율성과 지각적으로 충실한 결과 사이에서 좋은 균형을 이룹니다
4.2. Image Generation with Latent Diffusion
2562 이미지에 대한 비조건부 모델을 CelebA-HQ, FFHQ, LSUN-Churches 및 -Bedrooms 등의 데이터셋에서 훈련하고 평가합니다. 이 모델은 이전 likelihood 기반 모델과 GANs를 능가하는 새로운 최고의 FID를 달성합니다



▲Table 1
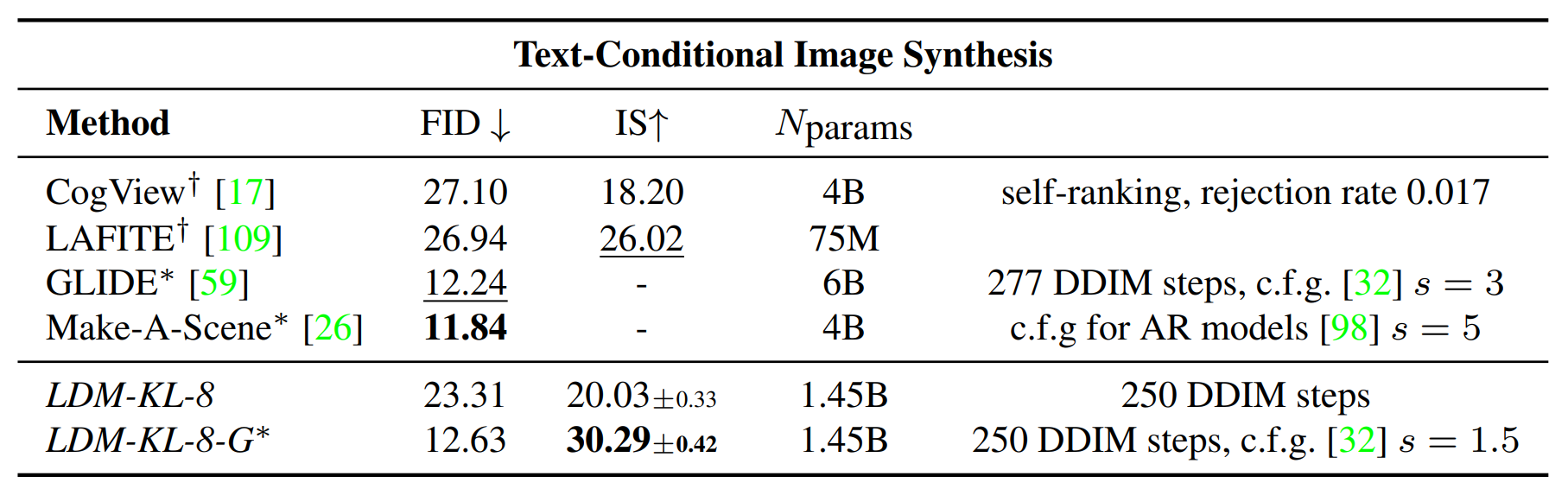
▲Table 2
4.3. Conditional Latent Diffusion
4.3.1 Transformer Encoders for LDMs
LDM에 cross-attention 기반 조건을 도입하여 다양한 조건부 모달리티에 대해 열린 모델을 소개합니다. 텍스트-이미지 모델링을 위해, BERT-tokenizer를 사용하여 언어 프롬프트에 대한 조건부 1.45B 매개변수 KL-regularized LDM을 훈련합니다.
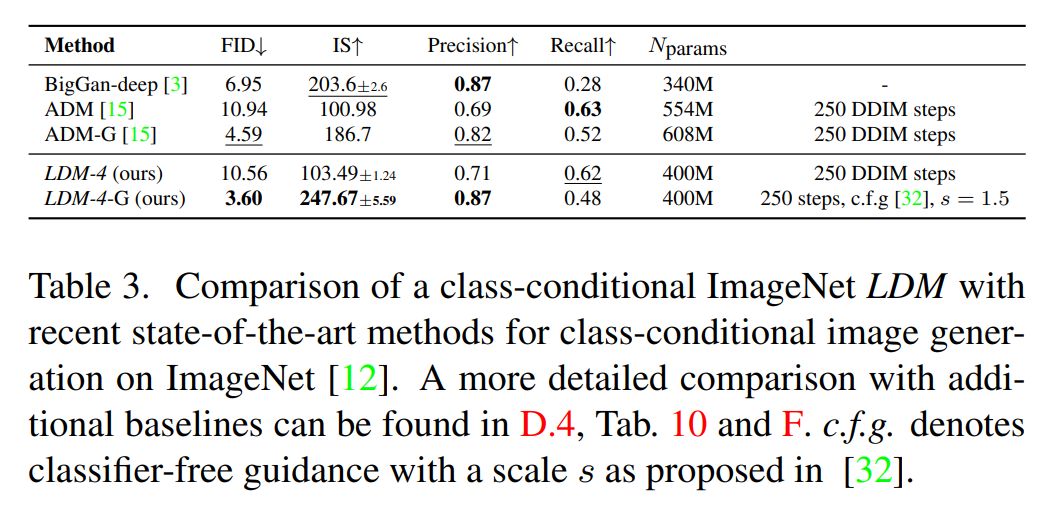
4.3.2 Convolutional Sampling Beyond
LDM을 일반적인 이미지-이미지 변환 모델로 사용하여 의미론적 합성, 초해상도 및 인페인팅에 대한 모델을 훈련합니다

4.4. Super-Resolution with Latent Diffusion
저해상도 이미지에 직접 조건을 부여하여 LDM을 훈련할 수 있습니다. 이 모델은 SR3의 성능을 능가하며, FID 점수에서 우수하지만 IS에서는 SR3가 더 높은 점수를 받습니다

4.5. Inpainting with Latent Diffusion
이 섹션은 이미지의 손상된 부분을 새로운 내용으로 채우는 인페인팅 작업에 대해 다룹니다. 이 모델은 기존 인페인팅 접근법과 비교하여 전반적인 이미지 품질을 FID로 향상시키며, 다양한 결과를 생성합니다

5. Limitations & Societal Impact
한계: LDM은 픽셀 기반 접근법에 비해 계산 요구사항을 크게 줄이지만, 그들의 순차적 샘플링 과정은 여전히 GAN보다 느리다. 또한, 높은 정밀도가 요구될 때 LDM 사용이 문제가 될 수 있다: f = 4 autoencoding 모델의 이미지 품질 손실은 매우 적지만, 픽셀 공간에서 미세한 정확성이 요구되는 작업의 경우 재구성 능력이 병목 현상이 될 수 있다.
| 논문에서 f=4 autoencoding은 이미지의 차원을 감소시키는 과정을 말합니다. 여기서 f는 공간 다운샘플링 요소로, 이미지의 해상도를 낮추는 비율을 나타냅니다. f=4는 원본 해상도에서 가로 및 세로 방향으로 각각 4분의 1로 다운샘플링된다는 것을 의미합니다. 이 과정은 오토인코더 모델을 사용하여 실행되며, 이미지에서 중요한 지각적 정보를 유지하면서도 데이터의 차원을 크게 줄이는 효과가 있습니다. 이렇게 차원이 축소된 이미지는 확산 모델이 훈련할 때 계산 비용을 크게 줄이면서도 높은 품질의 이미지 합성을 가능하게 합니다. |
사회적 영향: 이미지와 같은 미디어를 위한 생성 모델은 양날의 검이다. 한편으로는 다양한 창의적 응용 프로그램을 가능하게 하며, 특히 훈련 및 추론 비용을 줄이는 우리와 같은 접근 방식은 이 기술에 대한 접근을 용이하게 하고 탐색을 민주화할 잠재력을 가지고 있다. 반면에, 이는 조작된 데이터를 생성하고 퍼뜨리거나 잘못된 정보와 스팸을 퍼뜨리기 쉽게 만든다. 특히, 이미지의 고의적 조작(“딥페이크”)은 이 맥락에서 흔한 문제이며, 특히 여성들이 이로 인해 불균형하게 영향을 받는다. 생성 모델은 또한 민감하거나 개인적인 정보를 포함하고 명시적 동의 없이 수집된 훈련 데이터를 드러낼 수 있다. 그러나 이것이 이미지의 DM에도 어느 정도 적용되는지는 아직 완전히 이해되지 않았다. 마지막으로, 딥러닝 모듈은 데이터에 이미 존재하는 편견을 재생산하거나 악화시키는 경향이 있다. 확산 모델은 예를 들어 GAN 기반 접근법보다 데이터 분포를 더 잘 커버하지만, 적대적 훈련과 가능성 기반 목표를 결합하는 우리의 두 단계 접근 방식이 데이터를 얼마나 잘못 표현하는지는 중요한 연구 질문이 남아 있다.
6. Conclusion
결론에서는 잠재 확산 모델(Latent Diffusion Models, LDMs)을 제시하고 있습니다. 이 모델들은 디노이징 확산 모델의 훈련 및 샘플링 효율성을 크게 향상시키는 동시에 품질을 저하시키지 않는 간단하고 효율적인 방법으로 설명됩니다. 크로스 어텐션 조건부 메커니즘을 기반으로 한 실험을 통해, LDM은 다양한 조건부 이미지 합성 작업에서 최신 방법들에 비해 유리한 결과를 보였으며, 특정 작업에 특화된 아키텍처 없이도 이를 달성하였습니다.



