
https://arxiv.org/abs/1506.02640
You Only Look Once: Unified, Real-Time Object Detection
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabili
arxiv.org
Abstract
- 객체 탐지 및 분류를 하나의 신경망으로 진행하는 YOLO model을 제시
- 단일화된 과정으로 기존의 Object Detection model 대비 향상된 성능 비교
Introduction
- Object Detection이란?
- 이미지 내의 여러 Object(서로 다른 Class)를 Detection
- Object를 찾아 Bounding box를 형성
- YOLO란?
You Only Look Once 의 줄임말로
이미지를 한 번만(1-stage) 보고 Object Detection을 수행하는 model
- 2-Stage Detection
기존의 Object Detection 시스템은 두 단계(2-stage)로 진행
1. 이미지 내에서 분류해야 하는 객체를 탐색
원본 이미지에서 Object가 있을 확률이 높은 위치 계산 - Proposed Region
2. 탐색한 객체를 실제 분류
원본 이미지를 Classification layer에 태워 Feature maps 형성
형성한 map에 Proposed Region을 비율에 맞춰 투영, 분류
이는 각각의 모델을 따로따로 학습해야 하므로 시간이 오래 걸리는 단점이 있다.
- 1-Stage Detection
반면, 1-stage로 진행하게 되면
1. 객체의 위치 탐색과 분류를 동시에 진행
원본 이미지가 Conv layer와 FC layer를 거쳐 Output Tensor 형성
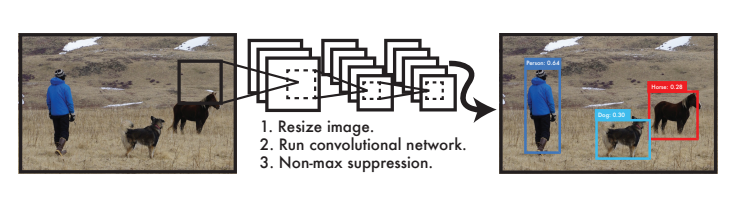
YOLO는 객체 탐색과 분류를 1-stage로 통합해 진행하는 모델로
객체가 존재할 것 같은 위치에 Bounding box를 형성함과 동시에 그 객체가 속한 Class를 분류한다.
따라서 이미지를 한 번만 봐도 객체를 인식할 수 있는 것이다.
즉, 단일화된 Object Detection의 단계로 속도를 개선한 것이 YOLO model이라 볼 수 있다.
YOLO model의 과정
- Unified Detection (단일화)
이미지의 feature map 형성과 bounding box, classification 모두 한 단계에서 진행
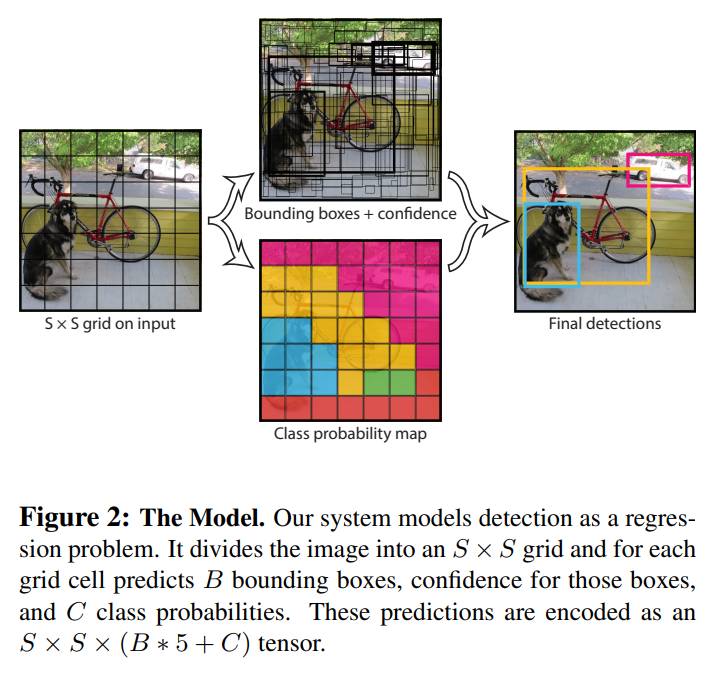
다음과 같은 과정으로 output tensor를 형성한다.
1. 입력된 이미지를 S*S 크기의 grid cell로 구분
2. 각 cell마다 Bounding box B개와 각 box에 대한 신뢰 점수를 예측
3. grid cell의 object가 각 클래스(총 C개)에 속할 확률 계산
4. Bounding box의 요소와 클래스에 속할 확률로 output tensor 형성
이때 Bounding box는 <x,y,w,h,신뢰도>의 요소를 가진다.
x, y 는 grid cell의 경계를 기준으로 하는 box의 중심 좌표
w, h 는 전체 이미지를 기준으로 normalize 된 너비와 높이
신뢰도는 bounding box에 실제 object가 있을 확률을 의미한다.
신뢰도는 다음과 같이 계산한다.

실제 object가 있는 box와 형성한 bounding box가 겹치는 정도를 표현하는 IOU(Intersection Over Union)를 사용하여 실제 object가 있을 확률을 계산할 수 있다.
- Network 구성

- GoogLeNet model을 기반 (단, inception module을 간소화)
- Image Feature를 추출하는 24개의 Conv Layer
- 예측을 수행하는 2개의 Fully Connected Layer
Training
Training : 본 실험에서 model을 어떻게 학습시킬 것인가
1. ImageNet 1000 데이터셋을 사용해 20개의 Conv layer를 Pre-training
(Image Feature 추출 단계)
이때, 세밀한 객체 인식을 위해 입력 해상도를 224*224에서 448*448로 높여준다.
2. 4개의 Conv layer와 2개의 FC layer 추가
(Detection을 수행할 수 있도록 구성해주는 단계)
마지막 FC layer는 Bounding box의 좌표와 인식한 객체의 클래스 확률을 예측
3. 활성 함수 Leaky ReLU(0.1), 손실 함수 SSE 사용
- 손실 함수 SSE(Sum Squared Error)

- 첫번째 항 : Object가 존재하는 grid cell i의 예측된 bounding box j에 대해 x,y의 loss 계산
- 두번째 항 : Object가 존재하는 grid cell i의 예측된 bounding box j에 대해 w,h의 loss 계산
- 세번째 항 : Object가 존재하는 grid cell i의 예측된 bounding box j에 대해 confidence score의 loss 계산
- 네번째 항 : Object가 존재하지 않는 grid cell i의 예측된 bounding box j에 대해 confidence score의 loss 계산
- 마지막 항 : Object가 존재하는 grid cell i에 대해 class에 속할 확률의 loss 계산
최종적으로 grid cell에 Object가 존재하는 경우의 오차와 예측 box로 선정되었을 때의 오차를 학습
4. 가장 IOU가 높은 하나의 box만을 사용
YOLO는 grid cell 당 여러 개의 Bounding box 예측이 존재
객체당 가장 예측력이 좋은 1개의 bounding box만을 가질 수 있도록 처리
- Non-maximal suppression
1. bounding box 각각이 class에 속할 confidence score를 계산
2. 높은 score 순으로 sorting 후 작은 score는 제거
3. 가장 높은 score의 bounding box를 그 다음으로 높은 score의 bounding box와 IOU 계산
4. IOU가 높으면 같은 object를 detect하고 있다고 판단하고 제거
5. class별로 수행
Experiment
1. Real-time으로 처리가 가능한지 확인하기 위해 일반적인 영상의 프레임 30FPS를 기준으로 확인
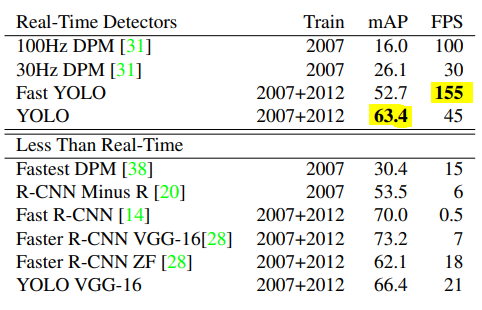
FAST YOLO : 가장 빠른 155FPS
YOLO : 45FPS, 가장 높은 mAP (mAP = mean Average Precision)
YOLO는 real-time 처리가 가능하며 성능이 매우 높다.
2. YOLO vs Fast R-CNN

결과 평가 기준
- Correct : class를 맞추고, 0.5<IOU
- Localization : class를 맞추고, 0.1<IOU<0.5
- Similar : 유사한 class로 예상하고, 0.1<IOU
- Other : class를 틀리고, 0.1<IOU
- Background : 모든 객체에서 IOU<0.1
YOLO의 경우 Fast R-CNN에 비해 Background가 매우 감소한 것을 확인할 수 있다.
이는 Background Error가 적은 것을 의미하며, 전체 이미지에서 객체와 배경을 잘 구분했다는 것을 의미한다.
추가로 Fast R-CNN과 YOLO를 ensemble하게 되면 성능이 유의미하게 더 높아지는 것을 확인할 수 있다.

3. Generalizability
YOLO model의 일반화 성능을 확인하기 위해 예술 작품으로 구성된 데이터셋으로 실험


다른 Object Detection 모델들에 비해 높은 성능 보여주는 것을 확인할 수 있고
예술 작품을 데이터로 진행했을 때에도 객체를 원활하게 인식하는 것을 확인할 수 있다.
한계점
- grid cell 당 하나의 Class만 예측하기 때문에 cell 안에 여러 개의 물체가 있으면 분류하기 어렵다
- 데이터로부터 Bounding box를 학습하므로, 일반적이지 않은 Bounding box는 형성하기 어렵다
- Bounding box의 크기가 달라져도 loss는 동일하므로 작은 box에서 위치가 부정확할 수 있다.
Conclusion
YOLO는 하나의 신경망으로 객체를 탐지 및 분류할 수 있는 모델로, 기존의 DPM, RCNN 모델보다 빠른 속도를 보여주기 때문에 Real-time detection이 가능하고 다양한 도메인에서 robust한 detection 성능을 보인다.



