
Preview
- 베이즈 정리
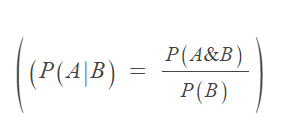
- 기본 조건부 확률의 정의를 이용한, 전확률 공식 활용.
- 사전분포를 이용해 사후분포를 표현할 때 활용
- MLE(Maximum Likelihood Estimator) : 최대가능도 추정량
- 통계학에서 주 관심사 중 하나. 가장 그럴듯한 정도(가능도)를 최대화 하는 값을 추정량으로 사용하는 것을 의미. 확률에 기반한 통계적 추정량으로, MLE는 수학적으로 여러가지 좋은 성질들을 가져, 통계학적으로 접근할 때, 가장 자주 고려되는 추정량이다. 여기서는 log(p(xi))의 최대화에 관심을가지며 이때의 최대 추정량에 이용.
- KLD(쿨백 라이블러 괴리도 or 발산)
- 두 분포의 차이를 나타내는 척도로 활용 같은 분포를 가지면 KL 값이 0 이며, 차이가 크면 클 수록 값이 커져서, KL >=0 이라는 성질이 존재함.
- 척도로서, 두 분포간 차이를 나타내기는 하지만, 수학적으로 사용되는 거리가 될 수는 없음. 대칭성을 만족하지 못하는 척도.
Abstract
- reparameterization of variational lower bound
- posterior inference
Introduction
- 다루기 힘든 사후 분포 최대화를 이뤄내기 위해, 수학적인 trick(reparameterization trick 등)을 활용 및 continous latent variable(연속형 잠재적 변수) 가정을 통해 사후분포 근사를 진행하고, likelihood 를 최대화 하는 것을 lower bound를 최소화 하는 수식으로 변형하여 최대화를 진행한다.
Method
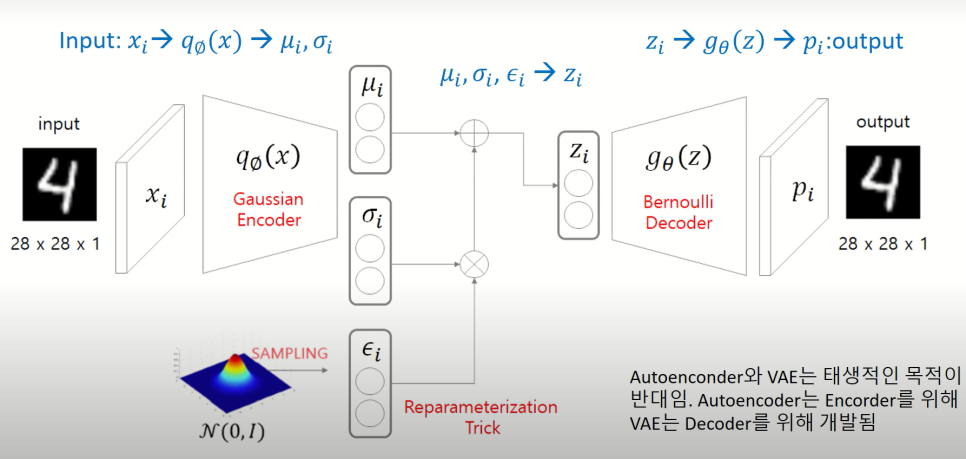
- input data에 대해, 정규분포의 parameter인 mu, sigma 로 차원 축소를 하고, 후의 계산을 위하여, reparameteriztion trick 을 활용하여, input data로 부터 추정한 mu, sigma의 정규분포로부터 sampling을 하여, z 값들을 뽑아내고, 이를 다시 decoder를 통해, 원래의 이미지와 비슷한 형태의 이미지를 생성해내는 generative model이라고 할 수 있다.

사후분포에 대한 접근 및 계산이 쉽지 않기 때문에, 직접 사후분포를 최대화하기는 쉽지 않고, 근사한 사후분포에 대해, lower bound를 최대화 하는 것으로 optimization을 진행하고자 하는것이다.
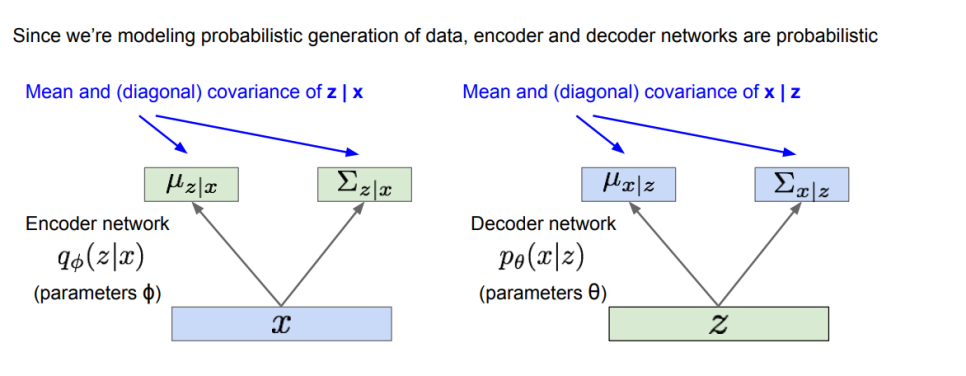
latent z space에 대해, z값은 참값인 모수 theta *에 의해 생성이 되었을 것이고, x라는 값들은 latent z가 conditioning된, 분포상에서 x가 생성된 것으로 보아,
참값 theta * 에 대해 위의 두 분포로부터 형성된 것으로 보고, 이를 추정해가는 과정.
Variational lower bound
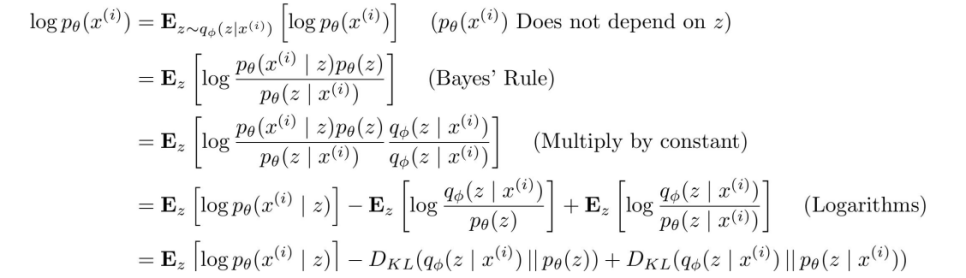
가장 그럴듯한 정도에 해당하는 모수 추정을 관측값인xi들로 확률적으로 표현한 logp(xi)
이 로그가능도를 최대화 하는것이 가능성을 가장 높이는 방향
베이즈정리와 log의 성질에 의해 log가능도는 reconsturct된 input data - x가주어졌을때의 KL(z의 사후분포, z의 모분포) + KL(z의 phi모수의 사후분포, z의 theta 모수의 사후분포)
로 나눠지게 된다. 이때 KL의 성질에 의해 KL >= 0 을 의미하고, = 0 을 만족하는 것은 둘의 분포가 아예 같다는 것을 의미한다.
마지막 term은 다루기가 힘들기는 하지만, 어쨌든 KL이므로 0 이상이라는 사실을 알고 있어서 앞의 두 term을 ELBO라고 하고, 이 ELBO를 최대화 하는 문제로 이해한다.
즉 log 가능도의 maximize는 E_z(logp_theta(xi|z) ) - KL(q_phi(z|xi), p_theta(z))을 최대화 하는 문제가 된다. 뒤의 KL term은 regularization이고, 앞의 term의 의미는 reconstruction error이다.
train과정에서 이 사실을 optimization문제로서 접근하여 활용.
Reparameterization trick
- 표준 정규분포에서 epsilon을 random sampling하고, 여기에 표준편차를 곱하고, 평균을 더해줌으로써, Z sampling을 수행.
- 단순 mu, sigma로부터의 sampling을 진행하면, backpropogation이 불가능하다는 단점을 위의 trick으로 해결
Summarise
input data에 대해, 이와 유사한 output을 생성해내는 generative model
이때, input data로부터, 적절한 가정(latent z space & normal분포 가정) 하에서, 확률적으로 z space의 모수를 잘 추정하고(베이즈 정리 및 베이지안 사후분포, 쿨백 라이블러 괴리도(발산) 등) 이 Z로부터 sampling을 통해, z를 생성, z를 decoder를 통과 시켜서 새로운 output을 만들어내는 모형이다.
확률모델, 분포가정 등 수리 통계적인 접근이 많이 존재한다.
참고



