
원본 논문 링크 : https://arxiv.org/abs/2402.16347
CodeS: Towards Building Open-source Language Models for Text-to-SQL
Language models have shown promising performance on the task of translating natural language questions into SQL queries (Text-to-SQL). However, most of the state-of-the-art (SOTA) approaches rely on powerful yet closed-source large language models (LLMs),
arxiv.org
Abstract
- 언어 모델은 자연어 질문을 SQL 쿼리로 변환하는 작업(Text-to-SQL)에서 유망한 성능을 보여주고 있다.
- 그러나 대부분의 SOTA(State-Of-The-Art)는 ChatGPT와 GPT-4와 같은 강력하지만 closed-source LLM에 의존하는데, 이러한 모델은 불명확한 모델 아키텍처, 데이터 프라이버시의 위험, 높은 inference cost 등의 한계가 있다.
- 이러한 한계를 해결하기 위해 저자는 Text-to-SQL task를 위한, 파라미터가 1B에서 15B까지의 pre-trained된 LM 시리즈인 CodeS를 소개한다.
- CodeS는 완전한 오픈 소스 LM으로, 훨씬 작은 파라미터 크기로 우수한 정확도를 달성했다.
- CodeS의 SQL 생성 능력을 향상시키기 위해, 저자들은 특정 SQL 중심의 corpus를 사용하여 incremental pre-training 접근 방식을 채택했다.
- 이를 바탕으로 schema linking 및 빠른 domain adaptation을 전략적인 prompt 구성과 bi-directional data augmentation을 통해 해결한다.
- 저자들은 여러가지 benchmark 데이터셋으로 포괄적으로 evaluation을 진행하였는데, 그들은 다음과 같다.
- Spider benchmark, 새로 출시된 BIRD benchmark , Spider-DK, Spider-Syn, Spider-Realistic 및 Dr.Spider와 같은 robustness를 진단하는 benchmark, 그리고 금융 도메인과 Academic 도메인에 응용하기 위해 본 논문에서 직접 구축한 두 개의 real-world 데이터셋
- 실험 결과, CodeS는 거의 대부분의 어려운 Text-to-SQL 벤치마크에 대해 SOTA를 달성하면서 동시에 두드러지는 robustness 또한 달성하였다.
1. Introduction
- Text-to-SQL task는 사용자의 자연어(NL) 질문을 해당 데이터베이스에서 실행할 수 있는 적절한 SQL 쿼리로 변환하는 것을 말한다.
- 아래 그림은 데이터베이스(예: 은행 금융)에 대한 NL(Natural Language) 질문이 SQL 쿼리로 변환되는 방식을 보여줍니다.

- Text-to-SQL은 SQL이나 데이터베이스 구조에 익숙하지 않은 사용자도 자연어를 사용하여 데이터베이스와 상호작용할 수 있도록 하여, 데이터베이스 및 자연어 처리 커뮤니티에서 점점 더 많은 관심을 받고 있습니다.
- 현재의 SOTA 방식은 장점과 한계가 있다. :
- 전통적인 Text-to-SQL은 Supervised Fine-Tuning (SFT) 접근 방식을 사용했지만, 최근에는 GPT-4, GPT-3.5 및 PaLM-2와 같은 LLM의 출현으로 패러다임이 바뀌기 시작했다.
- Fine-Tuning에 의존하기보다 LLM은 신중하게 설계된 프롬프트를 사용하여 Text-to-SQL에서 높은 성능을 보여주었으며, 이는 "Prompt learning" 또는 " In-context learning "으로 알려져 있다.
- 그러나 대부분의 SOTA 모델은 GPT-4 기반의 DIN-SQL, PaLM-2 기반의 SQL-PaLM, GPT-3.5 기반의 C3와 같은 closed-source LLM에 의존한다.
- 이러한 접근 방식은 유망한 Text-to-SQL 성능을 달성했지만, 다음과 같은 한계가 있을 수 있다.
- Closed-source 모델은 아키텍처와 training/inference 과정의 세부 사항을 숨기기 때문에 이들을 활용한 지속적인 개발을 방해할 수 있다.
- 이러한 모델을 API를 통해 호출하면 데이터를 모델 제공자에게 전송해야 하므로 데이터 프라이버시 위험이 있다.
- 대부분의 closed-source 모델은 많은 파라미터를 가지고 있어 inference overhead가 상당하며, 이는 일반적으로 API 호출 비용으로 반영된다. (즉, 돈이 많이 든다.)
- 이 논문에서 소개하는 CodeS는 오픈 소스 언어 모델이므로 위의 단점을 해결한다.
- CodeS는 code generation을 위해 설계된 최첨단 LLM인 StarCoder를 기반으로 하여 1B에서 15B까지 다양한 파라미터를 가지고 있다.
- 사용자는 자신의 computational resource에 맞춰 적절한 사이즈의 CodeS를 선택하여 Text-to-SQL 응용 프로그램을 구축할 수 있다.
- 아래 그래프에 나와 있듯이, 기존의 Text-to-SQL SOTA 모델들과 비교할 때 CodeS는 다음과 같은 장점을 가지고 있다.
- 완전히 오픈 소스인 LLM : StarCoder를 기반으로 한 CodeS는 완전히 오픈 소스이며 public으로 공개된다.
- 새로운 SOTA를 달성함 : CodeS는 Spider 및 BIRD와 같은, 수많은 어려운 Text-to-SQL 벤치마크에서 새로운 SOTA 성능을 달성했다.
- 사이즈가 작다 : CodeS는 ChatGPT 및 GPT-4와 같은 기존 SOTA LLM보다 10배에서 100배 더 작다.

- 저자들은 CodeS를 개발하는 데 있어 해결해야 했던 도전 과제를 설명하고 해결 방법을 다음과 같이 설명하였다.
- C1: 복잡한 Text-to-SQL reasoning 능력을 가진 소형 LM을 어떻게 만들 것인가?
- LLaMA-2 및 StarCoder와 같은 pre-trained LM을 직접 사용하는 것은 문제가 있다. 대부분 SQL과 관련된 훈련 corpus가 전체 pre-trained corpus에서 작은 부분만을 차지하기 때문이다.
- 따라서 데이터의 bias가 Text-to-SQL 기능을 저해할 수 있으며, pre-training 단계에서 LM은 SQL 관련 데이터의 분포보다는 전체 corpus의 분포에 맞추려 할 것이다.
- 더구나, ChatGPT와 GPT-4에 비해 소형 LM은 제한된 reasoning 능력을 가지고 있어 Text-to-SQL에서 충분한 능력을 발휘하지 못한다.
- 이 문제를 해결하기 위해, 저자들은 Text-to-SQL task와 관련된 거대하고 엄선된 데이터셋을 활용한 incremental pre-training 방식을 제안한다.
- 구체적으로, 저자들은 SQL-related 데이터 11GB, NL-to-code 데이터 6GB, NL-related 데이터 4.5GB로 구성된 21.5GB의 데이터를 수집하여 SQL 생성 능력과 자연어 이해를 향상시키고자 했다.
- StarCoder에 이 21.5GB의 corpus를 incremental pre-training함으로써, 저자들은 1B에서 15B까지 다양한 파라미터를 가진 CodeS 모델들을 만들었다.
- C2: schema linking의 어려움을 줄이기 위해 Text-to-SQL에 대한 고품질 prompt를 어떻게 생성할 것인가?
- Schema linking은 Text-to-SQL 변환에 매우 중요하며, 모델이 입력 질문을 특정 데이터베이스 요소에 매핑하도록 한다.
- 그러나 테이블이 많거나, 테이블에 열이 많서나, 테이블 또는 열의 이름이 모호하거나, 방대한 값이 있는 큰 테이블과 같은 경우에는 여러 이슈가 발생할 수 있다.
- 이를 해결하기 위해, 저자들은 많은 테이블과 큰 테이블에 대해 schema filtering 전략을 사용하여 데이터베이스에서 사용자의 쿼리에 관련된 테이블과 열만 유지하여 schema가 모델의 context 길이를 초과하지 않도록 한다.
- 모호한 이름(예: 약어)에 대해서는 이들에 주석을 추가하여 모델이 맥락을 이해하도록 돕는다.
- 큰 테이블에 대해서는 질문을 기반으로 BM25 인덱스를 사용하여 value를 일차적으로 필터링하고, the longest common substring 알고리즘을 사용하여 추가로 필터링하는 "coarse-to-fine" 방식을 사용한다.
- 이러한 기술들을 사용하여, 저자들은 CodeS 모델을 위한 프롬프트를 구성하여 schema linking을 향상시키고 복잡한 데이터베이스에 대한 Text-to-SQL 성능을 향상시킨다.
- C3: 새로운 도메인의 데이터베이스에서도 좋은 성능이 나오려면 어떻게 해야 하는가?
- 실제 상황에서는 CodeS 모델이 다양한 도메인에서도 성능이 잘 나와야 한다.
- 그러나 중요한 장애물은 fine-tuning을 위한 (question, SQL) pair가 부족하다는 것이다.
- 이 문제를 해결하기 위해, 저자들은 bi-directional data augmentation을 사용한다.
- 몇 가지 실제 사용자 쿼리를 수집하고, 해당 SQL 쿼리를 수동으로 주석을 단다. 그 후 GPT-3.5를 활용하여 더 많은 (question, SQL) pair들을 생성하여 사용자 지향적 진정성(user-oriented authenticity)을 보장한다.
- Text-to-SQL 벤치마크에 있는 SQL 템플릿과 question 템플릿을 사용한다. 새로운 도메인의 데이터베이스에서 테이블, 열, 값(value)을 삽입하여 다양한 (question, SQL) pair를 생성한다. 이 템플릿 접근 방식은 CodeS의 새로운 분포에 대한 적응성을 돕는다. 즉, 다양한 도메인에 대한 성능이 나오도록 한다. 이 논문에서 만들어진 training 데이터셋은 실제로 사용되는 사용자 쿼리 예제와 구조화된 템플릿을 결합하여 진정성과 광범위한 적용 가능성을 보장한다.
- Evaluation은 다음과 같이 시행된다.
- 저자들은 CodeS를 두 개의 어려운 Text-to-SQL 벤치마크인 Spider와 BIRD에 대해 evaluate 한다.
- Spider는 오랫동안 Text-to-SQL의 표준이고, BIRD는 더 복잡한 질문, 모호한 schema, 크고 지저분한 데이터베이스 값을 제공한다.
- 주요 Text-to-SQL method인 DIN-SQL+GPT-4는 테스트셋에서 약 56%의 performance를 달성한다.
- 전통적인 Spider 벤치마크 외에도, 저자들은 CodeS를 Spider의 네 가지 변형인 Spider-DK, Spider-Syn, Spider-Realistic 및 Dr.Spider에 대해 평가한다.
- 이는 총 20개의 테스트셋을 포함하며, test 데이터의 분포가 training 데이터의 분포와 다른 상황에서 모델의 성능을 파악할 수 있도록 설계되었다.
- 저자들은 새로운 도메인에 신속하게 적응하는 bi-directional data augmentation 방식의 효과를 파악하기 위해, Academic 및 금융 도메인의 데이터베이스를 추가로 만들었다. 두 데이터베이스 모두 fine-tuning을 하기에는 데이터가 충분하지 않았기 때문에, 이들은 training 데이터를 증강하고 모델을 fine-tuning한 후 각각의 테스트셋에서 성능을 평가했다.
- C1: 복잡한 Text-to-SQL reasoning 능력을 가진 소형 LM을 어떻게 만들 것인가?
- 이들의 기여를 요약하면 다음과 같다. :
- SQL 생성을 위해 설계된, 1B에서 15B 파라미터에 이르는 LM인 CodeS를 소개한다. 이는 SQL-related 데이터, NL-to-code 데이터, NL-related 데이터를 포함한 엄선된 pre-training corpus와 incremental pre-training 기법에 의해 구현된다. 이 접근 방식은 Text-to-SQL에 최적화된 LM에서 중요한 진전을 보인다.
- 우리는 포괄적인 데이터베이스 prompt를 사용하여 CodeS의 성능을 향상시킨다. 또한 새로운 도메인에 대해 적응하도록 하기 위해, annotation에 대한 부담을 줄일 수 있는 bi-directional data augmentation 방식을 도입한다.
- 여러 Text-to-SQL 벤치마크에 대한 다양한 평가를 통해 (1) CodeS가 SQL 생성 능력에서 다른 오픈 소스 pre-trained LM을 능가함을 보여주고, (2) fine-tuning된 경우, CodeS는 거의 모든 어려운 Text-to-SQL 벤치마크에서 새로운 SOTA 정확도와 robustness를 보여준다.
- 또한 이들은 GitHub에 이들의 코드, 모델 및 데이터를 오픈 소스로 공개하여, Text-to-SQL 분야의 커뮤니티에서 추가 연구, 채택 및 혁신을 촉진한다.
2. Related Work
이 논문에서는 Text-to-SQL에 대한 supervised fine-tuning과 prompting-based method를 다룬다. 또한 Text-to-SQL을 code generation의 하위 작업으로 볼 수 있기 때문에 기존 code LM을 탐구한다. 추가로, Text-to-SQL 방법론을 향상시키기 위해 제안된 다양한 schema linking과 data augmentation 기술도 살펴봅니다.
- Supervised Fine-Tuning-Based Text-to-SQL
- LLM 시대 이전에 Text-to-SQL의 주 접근 방식은 "인코더-디코더" 신경망 모델을 fine-tuning하는 것이었다.
- 쿼리 토큰, 테이블 및 열끼리의 그래프 구조 정보를 통합하여 질문과 데이터베이스를 인코딩하는 인코더의 표현 능력을 향상시키기 위해 많은 노력이 이루어졌다.
- 또 다른 노력으로는, 디코더의 출력 공간(출력 길이)을 제한하여, 올바른 SQL 쿼리 생성을 보장하는 SQL 문법을 디코더에 주입하는 데 중점을 두었다.(즉, 디코더에 입력되는 데이터 길이를 짧게 해서 정확하게 출력되도록 하는 것???)
- LM의 발전으로 Text-to-SQL을 sequence-to-sequence task로 포맷하는 경향이 증가하고 있기도 했다. 여기서 입력 시퀀스는 자연어 질문과 테이블, 열, 외래 키 등을 포함한 flatten된 데이터베이스 정보를 포함하고, 출력 시퀀스는 타겟팅하는 SQL 쿼리이다.
- 그런 다음 T5, BART와 같은 sequence-to-sequence 언어 모델이 이러한 입력-출력 문장 pair에 대해 fine-tuning 되어 제공된 입력으로부터 SQL 쿼리를 생성할 수 있게 한다.
- pre-training 기법의 주목할 만한 성과에서 영감을 받아, 몇몇의 연구들은, 방대한 데이터베이스 관련 데이터를 다양한 pre-training objective를 사용하여 LM을 pre-training하는 것을 진행했다.
- 그러나 본 논문의 CodeS와 달리, 이들의 주요 목표는 언어 모델의 SQL 생성 능력을 직접 향상시키는 것이 아니라, 질문과 데이터베이스 schema를 더 잘 표현할 수 있도록 인코더의 능력을 향상시키는 데 중점을 둔다. 그런 다음 이러한 pre-training된 인코더는 "인코더-디코더" 모델에 통합된다.
- Prompting-Based Text-to-SQL
- GPT-3, Codex, PaLM, LLaMA, StarCoder와 같은 LLM의 출현은 NLP 분야에 혁신적인 변화를 가져와, 파라미터를 fine-tuning하지 않고도 reasoning 능력을 필요로 하는 다양한 복잡한 작업에서 놀라운 진전을 이루었다.
- Text-to-SQL의 경우, 몇 가지 Text-to-SQL 데모를 few-shot prompt로 활용하여, SQL-PaLM(PaLM-2 기반) 및 Self-Debugging(Codex 기반)이 Spider에서 SOTA 성능을 성공적으로 달성했다.
- Chain-Of-Thought reasoning에서 영감을 받아, LLM의 Text-to-SQL 능력을 향상하기 위한 효과적인 prompt 설계가 뜨거운 연구 주제가 되었다.
- DIN-SQL(GPT-4 기반)은 Text-to-SQL task를 schema linking, query classification & decomposition, SQL generation 등 여러 간단한 sub-task로 나눈다.
- C3(ChatGPT 기반)는 ChatGPT에게 적절한 지침을 제공함으로써 좋은 zero-shot Text-to-SQL parser로 만든다.
- 이러한 prompt-based method는 Text-to-SQL 벤치마크에서 SOTA 성능을 달성했지만, 위에서 분석한 바와 같이 이러한 모델의 API를 사용하는 데 따른 상당한 비용과 잠재적인 데이터 프라이버시 문제로 인해 실제로는 구현하기 어렵다.
- Code Language Models
- 지난 몇 년 동안 코드 이해 및 생성과 같은 코딩 관련 task를 위해 LM을 활용하는 것에 대한 관심이 높아지고 있다.
- 기존 코드 LM은 종종 C, C++, Python, Java, C#, SQL과 같은 다양한 프로그래밍 언어에 대해 pre-training 되었다.
- 이렇게 training 데이터가 다양하면, 특정 프로그래밍 언어(이 논문에서는 SQL)에 대해 성능이 잘 안나올 수 있고 특히 소규모 모델에서 성능이 나오거나 최적화되기 어렵다.
- 이 문제를 해결하기 위해, 본 논문에서는 SQL 중심 데이터셋을 사용하여 Text-to-SQL에 최적화된 오픈 소스 생성 LM인 CodeS를 개발했다.
- Schema Linking
- Schema Linking은 자연어 질문 내에서 참조된 데이터베이스 Schema(예: 테이블 또는 열) 및 데이터베이스 Value를 식별하는 것을 목표로 하는 Text-to-SQL에서 중요한 역할을 한다.
- Schema Linking에는 주로 문자열 일치 기반 과 신경망 기반의 두 가지 전략이 있다.
- 문자열 일치 기반 접근 방식은 간단하지만 효과적으로 질문과 관련된 Schema와 Value를 직접 문자열 일치로 식별한다. 그러나 이 방식은 동의어 처리와 같은 특정 상황에서 한계가 있다.
- 이러한 문제를 해결하기 위해 신경망 기반 방법이 개발되었다. 이러한 방법은 Schema와 Value의 관련성을 semantic 레벨에서 평가하도록 설계되었다.
- Schema Linking 결과가 도출되면(예를 들어 모든 테이블과 열에 대한 일치 정도가 도출되면) 이러한 결과를 Text-to-SQL 모델의 추가 입력으로 통합한다.
- 참고로, RESDSQL은 Schema Linking 결과를 Schema pruning에 활용하여 이후 신경망 입력에 가장 관련성이 높은 Schema만 유지하여 LLM의 입력 길이를 줄인다.
- Text-to-SQL 을 위한 Data Augmentation
- 최근 Text-to-SQL을 위한 데이터를 합성하는 것에 대한 관심이 증가하고 있다. 그 목표는 주어진 데이터베이스와 관련된 (question, SQL) pair를 자동으로 생성하는 것이다.
- 현재 많은 방법들은 SQL- question 합성 파이프라인을 사용한다. 이 과정은 일반적으로 먼저 데이터베이스에 따라 자동으로 SQL 쿼리를 생성하고, 그런 다음 이러한 쿼리를 sequence-to-sequence 모델을 사용하여 자연어 질문으로 번역하는 것을 포함한다.
- 그러나 이러한 방법의 주목할 만한 단점은 합성된 자연어 질문이 실제 사용자와 현저히 다를 수 있다는 것이다.
- 이를 해결하기 위해, 본 논문에서 새로운 bi-directional data augmentation 전략을 제안한다. 이 방식은 SQL-question 합성 뿐만 아니라, question-SQL 합성 또한 진행하여 실제 사용자들이 할 수 있는 다양한 질문을 더 정확하게 생성한다.
3. Preliminaries
- Text-to-SQL Task
- Text-to-SQL 의 목표는 자연어 질문 Q와 데이터베이스 D를 기반으로 SQL 쿼리 S를 생성하는 것이다.
- SQL 쿼리는 질문에 답하기 위해 실행될 수 있어야 하고 다음과 같이 표현된다.: S = Parser(Q, D)
- 여기서 Parser()는 제공된 Q를 D를 사용하여 해석하고 S를 생성하도록 설계되었다.
- D는 데이터베이스 schema(예: 테이블과 열)와 열 유형, 주석, 열 value, 기본 키 및 외래 키 관계를 포함한 데이터베이스의 메타데이터를 포함한다.
- Pre-trained Language Models
- 주로 Transformer 아키텍처를 기반으로 하는 LM은 텍스트 이해 및 생성 작업에서 뛰어난 성능을 보인다.
- 이 모델들은 보통 광범위한 텍스트 데이터를 사용한 unsupervised learning objective으로 초기 pre-training 단계를 거친다.
- 두 가지 주요 unsupervised learning 패러다임은 “language modeling” 과 “masked language modeling"이다.
- 전자의 경우, GPT, PaLM, LLaMa와 같은 모델에 적용된 방법인데, 주어진 문맥에서 다음 단어를 예측하는 방식이다.
- 후자의 경우, BERT, RoBERTa, T5와 같은 모델에 적용된 방법인데, 입력 텍스트 내 특정 단어나 span이 무작위로 마스킹되고, 마스킹된 부분을 복원하는 작업을 수행한다.
- Supervised Fine-Tuning and In-context Learning
- pre-training된 LM은 광범위한 언어 지식을 보유하고 있지만, 특정 task는 고유한 언어 패턴이나 도메인 전문 지식을 요구하는 경우가 많다.
- 이를 해결하기 위해, Supervised Fine-Tuning(SFT)은 모델을 task-specific labeled 데이터로 추가 학습하여 초기 pre-training과 새로운 데이터셋에서 얻은 통찰력을 둘 다 활용한다.
- SFT와 달리, " In-context Learning" 개념은 적절한 프롬프트를 입력에 제공함으로써 언어 모델이 추가 학습 없이 새로운 task를 수행할 수 있게 한다. 그러나 context 내 학습의 효과는 프롬프트의 품질과 LM 자체의 성능에 크게 의존한다.
4. Overview
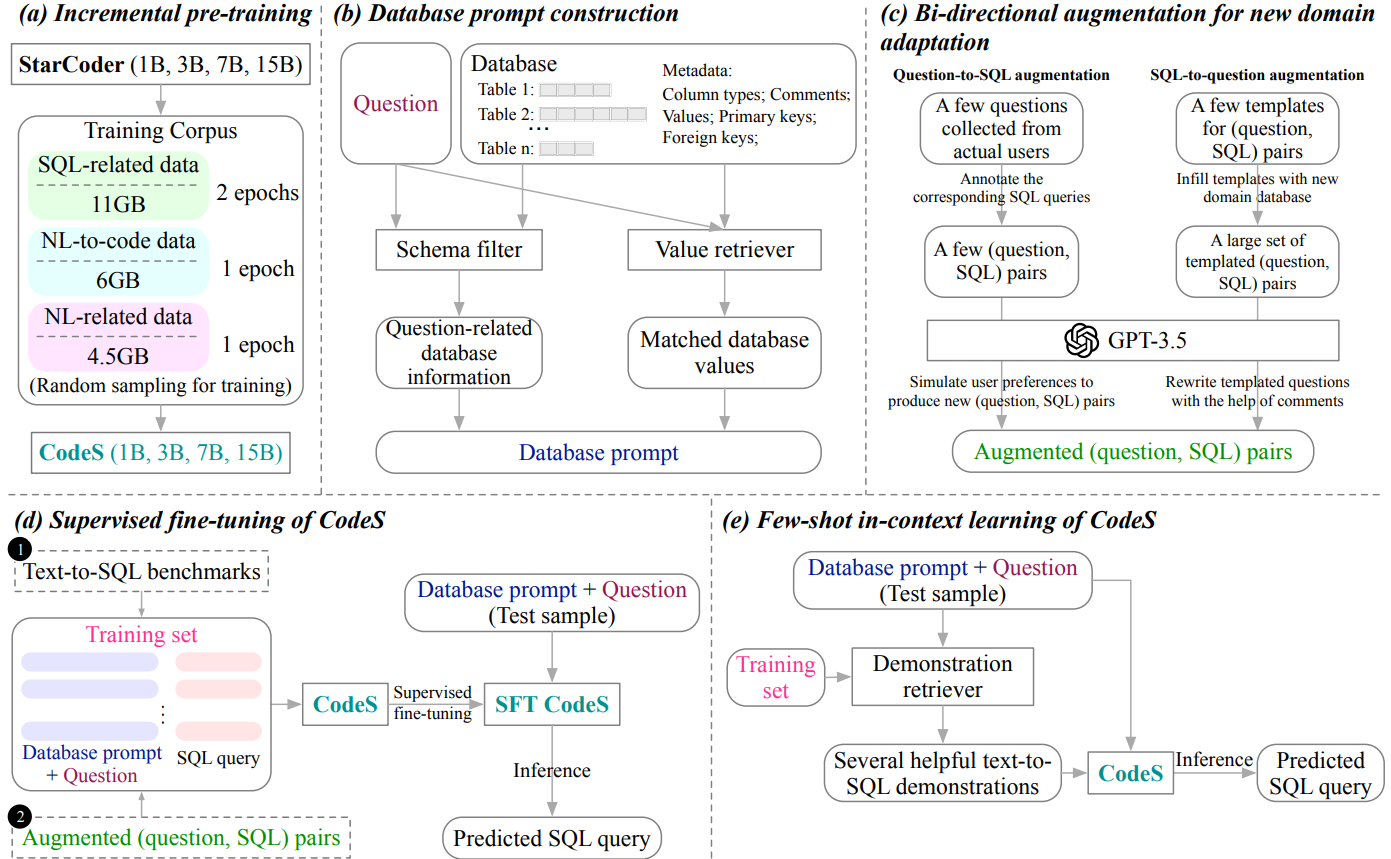
위 그림은 본 논문의 전체적인 과정을 보여준다. 저자들 강력하고 간결한 Text-to-SQL 모델을 개발하기 위해 세 가지 구성 요소를 도입하고 CodeS의 유연한 사용법을 보여준다.
- Incremental Pre-training (그림의 (a))
- 기존 언어 모델의 SQL 생성 및 자연어 이해 능력을 향상시키기 위해, 이들은 먼저 11GB의 SQL-related 데이터, 6GB의 NL-to-code 데이터, 4.5GB의 NL-related 데이터로 구성된 새로운 Corpus를 수집한다.
- 그런 다음 StarCoder를 기반으로 SQL 중심의 corpus를 사용하여 incremental pre-training을 수행하여 1B, 3B, 7B, 15B의 pre-trained된 CodeS를 얻는다.
- Database Prompt Construction (그림의 (b))
- 고품질의 데이터베이스 프롬프트를 생성하기 위해 포괄적인 데이터베이스 프롬프트 Construction 방식을 제시한다.
- 이 전략은 schema filter와 value retriever를 포함한다.
- schema filter는 주어진 질문에 따라 관련 없는 테이블과 열을 제거하기 위해 사용된다.
- value retriever는 질문과 일치하는 잠재적으로 유용한 데이터베이스 값을 추출하도록 사용된다.
- 테이블과 열 이름 외에도 데이터 유형, 주석, 대표적인 열의 값, 기본 키 및 외래 키에 대한 정보를 포함한 다양한 메타데이터를 추가로 프롬프트에 통합하여, Text-to-SQL 모델에 풍부한 context를 제공한다.
- New Domain Adaptation (그림의 (c))
- 새로운 도메인 데이터베이스에 대해 방대한 (question, SQL) pair를 생성하기 위한 bi-directional data augmentation 방법을 제시합니다.
- question-to-SQL 방향에서는 몇 가지 실제 question과 그에 대한 SQL을 짝지어서 라벨링하고, 이를 GPT-3.5를 사용하여 확장한다.
- SQL-to- question 방향에서는 기존 Text-to-SQL 벤치마크에서 템플릿을 추출하여 새로운 데이터베이스의 schema로 템플릿을 채우고, GPT-3.5로 질문을 다듬는다.
- 이 bi-directional 전략은 최소한의 annotation으로 강력한 training dataset을 생성하여 새로운 도메인에 대한 모델 fine-tuning을 용이하게 한다.
- CodeS의 사용법 (그림의 (d)와 (e))
- training data가 충분할 경우, CodeS의 파라미터를 직접 fine-tuning하여 라벨 데이터의 분포와 최대한으로 일치시킬 수 있다 (그림 (d)).
- 반대로, training data가 충분하지 않을 경우, 몇 가지 Text-to-SQL 데모만 제공하여 CodeS의 in-context learning 능력을 활용한다 (그림 3(e)).
- question의 유사성과 question의 패턴 유사성을 동시에 고려하여 유용한 데모를 추출하는 demonstration retriever를 도입한다.
- Complexity Discussion
- 어떤 제안된 솔루션의 다양한 구성 요소로 구성된 복잡성을 논의할 때, 오프라인 프로세스와 온라인 프로세스를 구별하는 것이 중요하다.
- incremental pre-training 과 new domain adaptation은 오프라인에서 수행되며, 이는 한 번만 실행된다.
- 반면, database prompt construction 전략은 온라인 프로세스로, inference 중 각 사용자의 쿼리에 응답해야 한다.
- 프롬프트 구성의 복잡성은 주로 schema filter와 value retriever의 두 가지 주요 구성 요소에서 발생한다.
- schema filter는 분류를 위해 간단한 신경망을 사용하여 빠른 추론 속도를 보여준다.
- value retriever의 효율성은 BM25 인덱싱을 사용하여 처리 속도를 향상시킨다.
5. Incremental Pre-training
5.1. Pre-training Corpus
Text-to-SQL 모델의 SQL 생성 및 자연어 이해 능력을 향상시키기 위해 SQL-related 데이터, NL-related 데이터, 그리고 NL-to-code 데이터를 수집한다.
- SQL-related data [11GB]
- 언어 모델의 SQL 생성 능력을 더욱 향상시키기 위해 StarCoder의 pre-training corpus에서 SQL segment를 사용한다.
- NL-related data [4.5GB]
- 자연어 이해 능력을 강화하기 위해 세 가지 출처에서 4.5GB의 고품질 대화 데이터를 샘플링한다
- Alpaca-cleaned는 지시를 따르는 LM을 개발하기 위해 설계된 데이터셋으로, OpenAI의 text-davinci-003 모델의 도움을 받아 self-instruct 기법을 사용하여 구축되었다.
- Unnatural-instructions는 인간의 개입이 거의 없이 수집된 대규모 instruction-following 데이터셋다. Alpaca-cleaned와 Unnatural-instructions 데이터셋은 모두 single-turn dialogue이다.
- UltraChat는 두 개의 서로 다른 GPT-3.5 API를 반복적으로 호출하여 생성된 multi-turn dialogue 데이터셋이다.
- 자연어 이해 능력을 강화하기 위해 세 가지 출처에서 4.5GB의 고품질 대화 데이터를 샘플링한다
- NL-to-code data [6GB]
- 자연어 질문과 SQL 쿼리 사이의 격차를 줄이기 위해 네 가지 유형의 NL-code 데이터셋을 pre-training corpus 에 통합한다
- CoNaLa와 StaQC는 Stack Overflow에서 자동으로 파생되었으며, 많은 자연어-파이썬 및 자연어-SQL pair를 포함다.
- CodeAlpaca-20k는 self-instruct 방법론을 사용하여 생성된 코드 관련 self-instruct 데이터를 포함다.
- Jupyter-structured-clean-dedup은 StarCoder의 pre-training corpus의 하위 집합으로, 코드와 함께 자연어 설명을 포함하는 구조화된 Jupyter Notebook 모음이다.
- 이전에 언급된 데이터셋과 달리, NL-SQL-458K는 논문 저자들 새로 제작한 데이터셋으로, 방대한 수의 자연어-SQL pair을 포함한다. 특히, 이들은 The Pile, The Stack, GitHub Code와 같은 세 개의 방대한 오픈 소스 corpus에서 정규 표현식을 사용하여 모든 "SELECT" 쿼리를 추출했다. 그런 다음 구문 오류가 있는 쿼리를 필터링하여 458K의 SQL 쿼리를 얻었다. 여덟 쌍의 (SQL, question) 데모를 프롬프트로 사용하여 GPT-3.5를 통해 각 SQL 쿼리에 해당하는 자연어 질문을 생성했다.
- 자연어 질문과 SQL 쿼리 사이의 격차를 줄이기 위해 네 가지 유형의 NL-code 데이터셋을 pre-training corpus 에 통합한다
5.2. Pre-Training Details
- CodeS는 StarCoder를 기반으로 구축되었으며, 이는 C, Python, Java, PHP, SQL 등을 포함한 80개 이상의 프로그래밍 언어, Jupyter Notebook, GitHub issue, Git commit의 혼합으로 pre-training된 오픈 소스 코드 언어 모델이다.
- CodeS를 개발하기 위해 저자들은 SQL-related 데이터에 대해 2 epoch, NL-related 데이터와 NL-to-code 데이터에 대해 각각 1 epoch씩 StarCoder를 incrementally pre-traing한다.
- 자연어와 코드에서의 혼합된 학습은 두 도메인 모두에서 다양한 작업에 이점을 제공한다.
- CodeS-15B는 StarCoder-15B를 기반으로 하고, CodeS-(1B, 3B, 7B)는 각각 StarCoderBase-(1B, 3B, 7B)에서 파생되었다.
- 그런 다음 GPT와 LLaMA와 같은 이전 pre-training된 LM에서 널리 사용된 language modeling objective를 최적화한다.
- 구체적으로, n개의 토큰으로 구성된 시퀀스 𝑥가 주어졌을 때, 우리의 목표는 전체 시퀀스의 likelihood을 최대화하는 것이다. 이 목표는 각 토큰에 대한 조건부 확률의 곱을 계산하여 달성됩니다:
$p(x) = \prod_{i=1}^{n-1} p(t_i | t_1, t_2, ... t_{i-1})$ - 최적화를 위해 AdamW 옵티마이저를 사용하며, 파라미터는 $\beta_1 = 0.9$, $\beta_2 = 0.95$ , $\epsilon = 10^{-8}$ 로 설정한다. 학습률은 $5e^{-5}$로 설정되며, weight decay는 0.1이다.
- learning rate scheduler는 워밍업 단계 없이 cosine decay를 쓰고, 최종 learning rate는 초기 값의 10분의 1로 설정된다.
- 학습 과정에서는 4M 토큰으로 구성된 큰 batch size를 사용하며, 안정성을 위해 1.0의 clipping 값을 사용하여 gradient clipping을 적용한다.
- 이들은 pre-training 중 GPU 메모리 소비를 최적화하기 위해 BF16 mixed precision을 사용하는 DeepSpeed Zero-3 프레임워크를 활용했다.
- 모델 아키텍처에 대한 자세한 내용은 아래 표에서 찾을 수 있다.

- CodeS에는 FlashAttention-2를 통합하여 확장된 context 길이를 처리하는 능력을 향상시켰다.
- 그러나 GPU 메모리 제한으로 인해 CodeS-(1B, 3B, 7B)는 최대 context 길이가 8,192로 제한되며, CodeS-15B는 6,144로 제한된다.
- 실제로, 이들이 수집한 corpus에 대한 incremental pre-training은 CodeS-(1B, 3B, 7B, 15B)에 대해 각각 약 1.5일, 3일, 8일, 16일이 소요되었다.
6. Database Prompt Construction
- 모델을 발전시키는 것 외에도 효과적인 데이터베이스 프롬프트 구축은 Text-to-SQL task에서 매우 중요하다.
- 고품질의 프롬프트는 LM에 좋은 통찰력을 제공하여 보다 효율적으로 정확한 SQL 쿼리를 생성할 수 있게 한다.
- 이런 우수한 데이터베이스 프롬프트를 제작하기 위해, 저자들은 schema filter와 value retriever라는 두 가지 전략을 사용하고, 뿐만 아니라 중요한 데이터베이스 메타데이터도 함께 프롬프트에 통합한다.
- 이들의 프롬프트 구성 프로세스를 설명하는 코드는 아래의 알고리즘으로 확인할 수 있다.

6.1. Schema Filter
- 실제 상황에서 데이터베이스는 종종 방대한 테이블과 열을 포함하며, 이는 매우 긴 데이터베이스 프롬프트를 초래한다.
- 이러한 프롬프트가 언어 모델의 최대 context 길이를 초과하면 잘라내야 하는데, 이 과정에서 목표하는 SQL 쿼리를 생성하는 데 필요한 중요한 테이블이나 열이 누락될 수 있다.
- 따라서 중요한 schema 정보를 희생하지 않으면서 데이터베이스 프롬프트 길이를 최소화하는 방법을 채택하는 것이 중요하다.
- 이들은 각 Text-to-SQL 샘플에 대해 데이터베이스 내에서 가장 관련성 높은 테이블과 열을 유지하기 위해 schema filter를 사용한다.
- 구체적으로, 데이터베이스와 질문이 주어지면, 사용자의 질문에 따라 테이블과 열의 관련성 점수를 예측하도록 학습된 schema item classifier를 개발했다.
- 이 점수를 사용하여 상위 $top_{k1}$의 테이블과 각 테이블에 대해 상위 $top_{k2}$의 열을 찾는다.
- 그런 다음, training 데이터셋의 Text-to-SQL 샘플에 대해 실제 SQL 쿼리가 제공되므로 사용된 테이블과 열을 직접 식별할 수 있다.
- test 데이터(여기서는 user가 입력하는 question을 의미함)와 training 데이터 간의 분포의 일관성을 유지하는 것을 목표로 하게 된다.
- 만약 사용된 테이블 수가 $top_{k1}$ 이하로 떨어지면 사용되지 않은 테이블 중 데이터베이스에서 무작위로 선택하여 마치 패딩처럼 사용한다. (근데 이럴 경우가 있나??)
- 열에 대해서도 유사한 절차를 채택하여 각각의 테이블이 $top_{k2}$의 열을 포함하도록 한다.
- schema filter의 통합은 데이터베이스 프롬프트의 길이를 줄일 뿐만 아니라 모델의 schema linking에 대한 부담도 완화된다.
6.2. Value Retriever
- 질문과 일치하는 데이터베이스의 value를 검색하면 모델이 SQL 쿼리의 조건을 생성할 때 더 나은 schema linking을 수행할 수 있다.
- BIRD 벤치마크의 "How many clients opened their accounts in Jesenik branch were women?"이라는 질문을 예로 들면, 데이터베이스 값과의 비교를 통해 "district" 테이블의 "a2" 열에 "Jesenik" 값이 포함되어 있음을 알 수 있다.
- 그런 다음 district.a2 = 'Jesenik'이라는 정보를 데이터베이스 프롬프트에 통합하여 모델이 SQL 쿼리에 대해 정확한 조건을 생성할 수 있도록 할 수 있다.
- 이전 연구에서는 일치 정도를 계산하기 위해 Longest Common Substring(LCS) 알고리즘을 사용한다.
- 그러나 이 알고리즘의 시간 복잡도는 입력 문자열 두 개의 길이를 𝑓와 𝑢로 나타낼 때 𝑂(𝑓 ∗ 𝑢)이다.
- 만약 데이터베이스에 방대한 값이 포함된 경우(예: BIRD 벤치마크의 Donor 데이터베이스는 약 116.5M 개의 valid value를 포함) 모든 데이터베이스 값에 대해 일치 정도를 계산하는 것은 너무 시간이 많이 소요된다.
- 이를 해결하기 위해 우리는 " coarse-to-fine" 매칭 접근 방식을 제안한다.
- 이 방법의 핵심은 빠르면서도 거친 초기 검색을 위해 인덱스를 사용하고, 그런 다음 LCS 알고리즘을 사용하여 미세한 매칭 과정을 수행하는 것이다.
- 구체적으로, 이들은 Lucene을 사용하여 각 데이터베이스에 저장된 모든 값에 대해 BM25 인덱스를 빌드한다.(Inference 이전에 이건 미리 해두게 된다.)
- 사용자의 질문이 접수되면, 인덱스는 질문에 따라 전체 데이터베이스에서 수백 개의 잠재적으로 관련성 있는 값만을 추출한다.
- 그런 다음 LCS를 사용하여 질문과 잠재적으로 관련성 있는 값 간의 일치 정도를 계산하여 가장 관련성 있는 값을 찾는다.
- BM25 인덱스와 LCS의 통합은 LCS 알고리즘 호출 횟수를 수백만 번에서 수백 번으로 크게 줄여 데이터베이스의 값 검색 속도를 크게 향상시킨다.
6.3 Database Metadata
우리의 데이터베이스 프롬프트에는 텍스트-투-SQL에 유용한 몇 가지 메타데이터도 추가합니다:
- Column Data Types
- 열의 데이터 타입은 유효성 검사 규칙과 operation이 실행되는지 여부를 결정한다.
- 예를 들어, INTEGER와 REAL 같은 숫자 타입은 산술 연산을 지원하지만 문자열 타입은 지원하지 않는다.
- 특정 데이터가 문자열 타입으로 저장된 경우, 산술 연산을 수행하기 전에 SQL 쿼리에서 CAST 함수를 사용해야한다.
- Comments
- 실제 데이터베이스 schema에서는 모호성이 흔히 발생한다.
- 아래 표는 BIRD 벤치마크에서 모호한 열의 예를 보여준다.

-
- 모호한 스키마는 모델이 생성한 SQL 쿼리에서 잘못된 테이블이나 열을 선택하도록 유도할 수 있다.
- 다행히도 데이터베이스는 모호한 스키마에 대해 유익한 주석을 제공하는 경우가 많다.
- 우리는 이러한 주석을 schema item classifier의 입력과 데이터베이스 프롬프트에 통합하여 LLM이 정확한 schema linking을 수행할 수 있도록 한다.
- Representative Database Values
- 열 이름 외에도 대표적인 열 value은 유용하게 쓰일 수 있다.
- 예를 들어, client.gender = 'F'와 같은 조건을 생성하려면 gender 열이 'M'과 'F' 두 value를 제공한다는 것을 모델에 알리는 것이 중요하다.
- 비슷하게, SUBSTR (hiredate, 1, 4) = '2009'와 같은 조건을 위해 모델은 "hiredate" 열의 특정 형식, "YYYY-MM-DD"를 알아야 한다.
- 그러나 Value Retriever로 얻을 수 있는 question과 일치하는 value가 이러한 미묘한 점을 다루지는 않는다.
- 이를 해결하기 위해 각 열에 대해 대표적인 값을 추출한다.
- 본 논문에서는 "SELECT DISTINCT {COLUMN} FROM {TABLE} WHERE {COLUMN} IS NOT NULL LIMIT 2"라는 SQL 쿼리를 사용하여 각 열에서 두 개의 고유한 대표적인 null이 아닌 값을 추출한다.
- 이러한 값을 제공함으로써, LM이 정확하고 맥락에 맞는 SQL 쿼리를 생성할 수 있게 된다.
- Primary and Foreign Keys
- 기본 키는 테이블의 각 행을 고유하게 식별하고, 외래 키는 테이블 간의 연관성을 보여준다.
- 기본 키 및 외래 키 정보를 통합하면 모델이 적절한 JOIN 경로를 추론하여 정확한 JOIN ON 절을 생성할 수 있다.
- 실제로, 본 논문에서도 각 기본 키 열에 고유 식별자를 사용하고, 각 외래 키를 데이터베이스 프롬프트 내에서 {TABLE1}.{COLUMN1} = {TABLE2}.{COLUMN2}로 표현한다.
아래 그림에서는 이 논문에서 제안된 전략을 사용하여 제작된 데이터베이스 프롬프트와 함께 Spider 벤치마크의 training 샘플을 보여준다. 사용자의 질문을 기반으로, reviewer.name 열에서 관련 데이터베이스 값인 Sarah Martinez가 추출된니다. 그런 다음 표시된 기본 키와 외래 키는 언어 모델이 JOIN ON 절을 생성하는 데 도움을 준다.

7. New Domain Adaptation
실제 상황에서 사람들은 보통 금융, 유전자, 생물학, 학계 등 다양한 새로운 도메인의 자신만의 데이터베이스를 가지고 있다. 그러나 이러한 데이터베이스에서 Text-to-SQL 모델을 개발하는 것은 레이블이 지정된 학습 데이터의 부족으로 인해 어려움을 겪는다. 이 섹션에서는 최소한의 annotation 비용으로 대량의 좋은 (question, SQL) pair를 자동으로 생성하는 bi-directional data augmentation을 제안한다.
- Question-to-SQL Augmentation
- 이 Augmentation 방향은 사용자 선호에 맞는 진정한 (question, SQL) pair를 생성하는 것을 목표로 한다.
- 구체적으로, 우리는 먼저 실제 Text-to-SQL 사용자로부터 몇 가지 진정한 대표적인 자연어 질문을 수집한다.
- 이러한 질문은 특정 데이터베이스에 대해 사용자가 가장 많이 하는 질문들에 해당한다.
- 그런 다음 이 질문들에 대응되는 SQL 쿼리를 사람이 직접 수동으로 annotate하여 몇 가지 고품질의 (question, SQL) pair를 얻는다.
- 자주 묻는 질문이 보통 그리 많지 않기 때문에 annotation 작업은 상대적으로 그리 많지 않다.
- 그러나 annotation된 데이터의 양이 제한되어 언어 모델을 직접 fine-tuning하기에는 충분하지 않다.
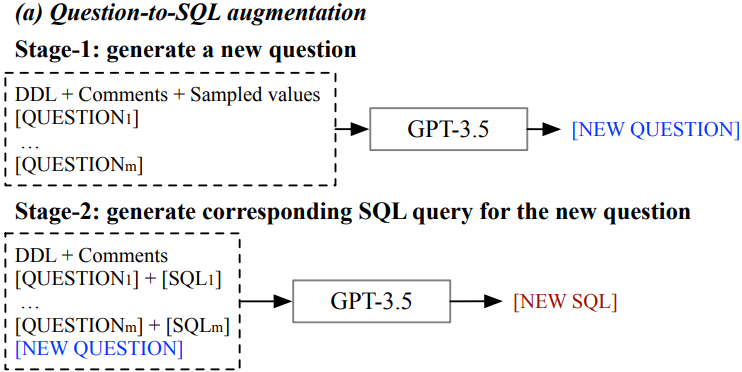
- 이를 해결하기 위해 이들은 두 단계의 프롬프트 접근 방식을 도입한다.
- 처음에는 GPT-3.5에게 수집된 실제 질문을 기반으로 잠재적인 질문을 생성하도록 프롬프트를 사용하여 사용자 의도를 포착한다.(즉, 수동으로 수집한 질문이랑 비슷한 질문들을 더 만든다.)
- 그런 다음 이러한 생성된 질문에 대해 대응하는 SQL 쿼리를 GPT-3.5를 통해 만든다.
- 아래 그림(a)는 이 두 단계 과정에서 사용된 프롬프트를 보여준다.
- 여기서 [QUESTION𝑖]와 [SQL𝑖]는 수동으로 annotation된 데이터 pair를 나타내며, 𝑚은 이러한 쌍의 총 수를 나타낸다.
- 새로 생성된 질문의 다양성을 보장하기 위해 사용자가 제공하는 질문의 순서를 섞고, 각 생성에 대해 높은 temperature 하이퍼파라미터를 사용한다.
- 마지막으로, [NEW QUESTION]과 [NEW SQL]은 사용자의 선호를 반영하는 새로운 데이터 쌍을 나타낸다.
- SQL-to-Question Augmentation
- SyntaxSQLNet에 영감을 받아, 이들은 범용 템플릿셋을 사용하여 일반적인 (question, SQL) pair를 생성하는 또 다른 augmentation 방법을 생각했다.
- 구체적으로, 널리 쓰이는 Text-to-SQL 벤치마크인 Spider에서 파생된 (question, SQL) 템플릿을 사용하여 75개의 일반적인 SQL 템플릿을 우선 선정한다.
- 예를 들어, 템플릿 질문은 “Return the lowest {COLUMN} of {TABLE}”와 그에 대응하는 템플릿 SQL인 “SELECT {COLUMN} FROM {TABLE} GROUP BY {COLUMN} ORDER BY COUNT (*) ASC LIMIT 1”이 있다.
- 자연 언어의 유연성으로 인해 단일 SQL 템플릿이 여러 질문 템플릿과 일치할 수 있다.
- 다음으로, 새로운 데이터베이스 schema로 슬롯을 채워 수많은 템플릿 (question, SQL) pair를 생성한다.
- 그러나 이러한 템플릿 질문은 테이블과 열 이름을 직접 삽입하기 때문에 인위적으로 보일 수 있다.
- 이러한 질문을 보다 자연스럽게 만들기 위해 GPT-3.5를 사용하여 𝑓개의 사람이 직접 수동으로 정제한 예시를 기반으로 다시 표현하도록 한다.
- 아래 그림(b)에서 보여지듯, 각 예시는 [TEMPLATED QUESTION𝑖], [TEMPLATED SQL𝑖], 및 [REFINED QUESTION𝑖]라는 세 개의 항목으로 구성된다.
- 최종 결과는 보다 일반적인 Text-to-SQL 데이터셋과 밀접하게 일치하는 [NEW REFINED QUESTION]과 [NEW TEMPLATED SQL]이라는 새로운 pair이다.

8. Usage of codes
- 이 논문은 CodeS를 fine-tuning과 few-shot in-context learning으로 사용합니다.
- Text-to-SQL 샘플 $ℎ$개의 학습 세트 $𝐷 = \{𝑑_{1}, 𝑑_{2}, ..., 𝑑_{ℎ}\}$가 주어졌을 때, 각 샘플은 데이터베이스, 질문 및 관련 SQL 쿼리를 나타내는 $(𝑑_{i}^{𝑑𝑏}, 𝑑_{𝑖}^{q}, 𝑑_{𝑖}^{sql})$ 이다.
- 데이터베이스 $𝑡^{𝑑𝑏}$ 및 질문 $𝑡^{𝑞}$로 구성된 테스트 샘플 $𝑡$에 대해, 우리는 SQL 쿼리 $𝑡^{𝑠𝑞𝑙}$을 생성하는 것을 목표로 한다.
- CodeS를 사용하기 전에 Text-to-SQL 샘플의 각 데이터베이스를 해당하는 데이터베이스 프롬프트로 변환합니다. (Section 6 참조)
- 따라서 각 training 샘플은 데이터베이스 $𝑑_{i}^{𝑑𝑏}$의 프롬프트인 $𝑑_{i}^{𝑑𝑏_{p}}$ 를 포함한 $(𝑑_{i}^{𝑑𝑏 _{p}}, 𝑑_{𝑖}^{q}, 𝑑_{𝑖}^{sql })$ 로 표현됩니다. 마찬가지로, 각 test 샘플은 데이터베이스 $𝑡^{𝑑𝑏}$ 의 프롬프트인 $𝑡^{𝑑𝑏_{p}}$를 포함한 쌍 $(𝑡^{𝑑𝑏_{p}} , 𝑡_{𝑞})$으로 변환됩니다.
8.1. Supervised Fine-Tuning
- 많은 양의 학습 데이터가 주어지면, Supervised Fine-Tuning(SFT)은 특정 데이터 분포에 신속하게 적응할 수 있으므로 선호된다.
- 입력 시퀀스를 데이터베이스 프롬프트와 질문의 조합으로 구성한다. 그런 다음 CodeS는 이 입력 시퀀스를 기반으로 원하는 SQL 쿼리를 예측하도록 최적화된다.
- 따라서 SFT CodeS의 학습 목표는 다음과 같다:
$ \text{Loss} = \frac{1}{ℎ} \sum_{𝑖=1}^{ℎ} \text{p}( 𝑑_{𝑖}^{sql} | 𝑑_{i}^{𝑑𝑏 _{p}}, 𝑑_{𝑖}^{q}) $ - Fine-Tuning 과정을 거친 후, 주어진 테스트 샘플에 대해, CodeS는 𝑡^{𝑑𝑏_{p}} 와 𝑡_{𝑞}가 결합된 입력값을 사용하여 SQL 쿼리를 쉽게 생성할 수 있다.
8.2. Few-shot In-Context Learning
- Fine-Tuning이 실현 불가능한 경우, 모델에 내장된 Text-to-SQL 기능을 활용할 수 있다.
- Few-shot learning 의 효율성은 모델의 내재적인 능력뿐만 아니라 프롬프트에 추가되는 예제에도 영향을 받는다.
- 따라서 우리는 효율적인 retriever를 사용하여 유용한 예제를 찾니다.
- 이들의 목표는 데이터셋 $𝐷$에서 $𝐾$개의 유용한 예제를 선택하여 모델이 올바른 SQL 쿼리를 예측하는 데 도움을 주는 것이다.
- 기본적인 방법은 테스트 질문 $𝑡^{𝑞}$와 모든 학습 질문 $\{𝑑_{1}^{q}, 𝑑_{2}^{q} , ..., 𝑑_{h}^{q} \}$ 사이의 semantic한 관련성을 확인하여 가장 잘 맞는 상위 𝐾개의 training 샘플을 얻는 것이다.
- 그러나 이는 Entity를 과도하게 우선시하여, 단순히 테스트 질문의 Entity를 반영하는 예제를 가져오는 결과를 초래할 수 있다.
- 예를 들어, 1948년 또는 1949년에 태어난 가수를 묻는 질문은 "가수와 노래"에 대한 공통되는 참조 때문에 가장 많은 노래를 부른 아티스트에 대한 training 질문을 가져올 수도 있다.
- Entity를 과도하게 강조하지 않기 위해 우리는 질문의 핵심 구조에 집중하여 Entity를 제거한다.
- 예를 들어, 1948년 또는 1949년에 태어난 가수에 대한 질문에 가장 적합한 예제 질문을 "미국 또는 캐나다 출신 멤버의 이름을 보여줘"로 설정하여 "가수와 노래"에 국한되지 않도록 한다.
- 테스트 질문 $𝑡^{𝑞}$와 training 질문 $𝑑_{𝑖}^{q}$ 사이의 유사도 점수는 다음과 같이 정의됩니다:
$\max(\text{sentsim}( t^{q} , d_{i}^{q} ), \text{sentsim}(t^{qs} , d_{i}^{qs})$ - 여기서 $ 𝑡^{𝑞s} $와 $ 𝑑_{𝑖}^{qs} $는 각각 $ 𝑡^{𝑞} $와 $ 𝑑_{𝑖}^{q} $ 에서 추출된 질문 패턴을 나타냅니다.
- nltk 라이브러리를 사용하여 질문에서 Entity를 식별하고 제거하여 패턴을 얻는다.
- 그런 다음 SimCSE, 문장 유사도 모델을 사용하여 시퀀스 유사도를 계산한다.
- 우리는 이 향상된 검색 접근 방식을 "question-pattern-aware demonstration retriever"라고 부릅니다.
- 마지막으로, 가장 관련성이 높은 $𝐾$개의 예제를 선택한 후, 우리는 이를 테스트 샘플과 병합하여 통합 입력 시퀀스를 생성한다.
- 이 시퀀스는 pre-trained 모델에 입력되어 SQL 쿼리를 도출한다.
9. Experiment
9.1 Experimental Setup
- 9.1.1 데이터셋
- 영어 text-to-SQL 벤치마크인 Spider와 BIRD에서 주요 실험을 수행했다. 또한, 네 가지 더 어려운 벤치마크인 Spider-DK, Spider-Syn, Spider-Realistic, 그리고 Dr.Spider에서도 모델의 robustness를 평가했다.
- 이들은 Spider를 training set으로 사용하고 이 robustness 진단 test set에서 모델을 평가했다.
- 또한, 금융 및 academic 분야에서 수동으로 생성한 두 개의 데이터베이스인 Bank-Financials와 Aminer-Simplified를 추가로 평가했다.
- Spider는 8,659개의 샘플로 구성된 training set과 1,034개의 샘플로 구성된 development set을 제공하며, 숨겨진 test set도 존재한다. training 부분은 수동으로 주석이 달린 7,000개의 샘플과, Restaurants, GeoQuery, Scholar, Academic, IMDB, Yelp 등 여섯 개의 이전 text-to-SQL 데이터셋에서 가져온 추가 1,659개의 샘플로 구성되어 있다. Spider는 138개의 다양한 도메인을 다루는 200개의 데이터베이스를 포함한다. 그러나 Spider 제출 플랫폼의 하드웨어 제한으로 인해 우리는 test set 에서 모델을 평가할 수 없습니다. 따라서 Spider의 경우 주요한 평가는 공개된 development set를 사용했다.
- BIRD는 9,428개의 샘플로 구성된 training set와 1,534개의 샘플로 구성된 development set, 그리고 숨겨진 test set를 포함합니다. BIRD는 37개의 고유한 전문 도메인을 아우르는 95개의 데이터베이스로 구성되며, 총 33.4GB의 데이터를 포함한다. BIRD의 각 데이터베이스는 평균적으로 약 549K개의 행을 포함하며, 이는 Spider의 제한된 2,000개의 행보다 훨씬 크다. 또한, BIRD는 특정 샘플에 대해 External Knowledge (EK)을 제공하여 올바른 SQL 쿼리 생성을 촉진한다. 사용자가 이러한 External Knowledge을 제공하는 것은 비현실적이기 때문에, 우리는 External Knowledge이 있는 경우와 없는 경우의 2가지 케이스로 BIRD를 평가했다. External Knowledge을 사용할 때, 저자들은 이를 질문과 통합하여 입력 프롬프트를 더욱 풍부하게 하여 생성한다. 이들들의 코드와 모델은 BIRD의 공식 주최자들에게 평가를 위해 제공되었다.
- Spider-DK, Spider-Syn, Spider-Realistic은 원래 Spider 데이터셋에서 파생된 변형들로, 실제 사용자들이 제기할 수 있는 질문을 모방하기 위해 설계되었다. Dr.Spider는 Spider의 파생형으로, 질문, 데이터베이스 및 SQL 쿼리 전반에 걸쳐 17개의 다양한 교란을 통합하여 text-to-SQL 모델의 robustness를 종합적으로 평가한다. 특히 Dr.Spider는 데이터베이스 교란을 반영한 3개의 test set, 질문 교란을 반영한 9개의 test set, 그리고 SQL 교란을 반영한 5개의 test set로 구성된다.
- Bank-Financials는 4개의 테이블을 포함하는 금융 데이터베이스에서 파생되었으며, 가장 큰 테이블은 65개의 열을 포함한다. bi-directional data augmentation을 사용하여 새로운 금융 데이터베이스에 대해 4,901개의 샘플로 구성된 훈련 세트를 생성했다. 평가를 위해, 추가로 91개의 실제 질문에 수동으로 annotation을 달아 test set을 만들었다.
- Aminer-Simplified는 대규모 학문 그래프인 AMiner에서 샘플링된 학문 데이터베이스에서 유래되었다. 이들은 Bank-Financials와 동일한 절차를 따라 5,427개의 샘플로 구성된 training set와 97개의 샘플로 구성된 test set 를 얻었습니다. 이 두 데이터셋의 training set은 모두 수동으로 annotation이 달린 30개의 샘플에서 파생되었다.
- 9.1.2 Evaluation Metrics
- Spider 계열 벤치마크(Spider, Spider-DK, Spider-Syn, Spider-Realistic, Dr.Spider 포함)의 경우, 두 가지 평가 지표인 execution accuracy (EX)와 test-suite accuracy (TS)를 사용했다. EX 지표는 예측된 SQL 쿼리와 실제 SQL 쿼리가 데이터베이스에서 동일한 실행 결과를 생성하는지 평가한다. 그러나 EX는 때때로 잘못된 SQL 예측이 우연히 올바른 쿼리와 동일한 출력을 생성하는 상황에서 false positive를 발생시킬 수 있다. 이를 해결하기 위해, TS는 여러 데이터베이스 인스턴스에서 EX 평가를 일관되게 통과하는지 평가한다. TS는 false positive을 줄이는 데 뛰어나므로 EX보다 더 신뢰할 수 있는 지표로 간주된다. Spider-DK와 Dr.Spider의 경우, TS script에는 해당 데이터베이스에 대한 test suites가 없으므로 EX 지표만 사용한다.
- BIRD 벤치마크는 주로 실행 정확도(EX)를 평가 지표로 사용한다. 이는 BIRD의 데이터베이스가 일반적으로 많은 수의 값을 포함하여 false positive의 가능성을 최소화하기 때문이다. 추가로, BIRD는 정확하게 생성된 SQL 쿼리의 실행 효율성을 평가하기 위해 valid efficiency score(VES)를 도입합니다. VES에서는 정확하게 생성된 SQL 쿼리의 점수가 더 이상 1이 아니며, 실제 SQL 쿼리의 실행 시간에 대한 예측된 SQL 쿼리의 실행 시간으로 결정된다. 따라서 실행 효율성이 동일하다면, EX와 VES의 점수는 동일하다. 그러나 예측된 SQL 쿼리가 실제 SQL 쿼리보다 빠르게 실행되면, VES 값은 EX보다 높아진다. 각 정확히 예측된 SQL 쿼리와 실제 SQL 쿼리는 100번 실행되며 실행 시간이 기록된다. 그러나 예비 실험은 VES가 하드웨어, 소프트웨어, 시스템 상태의 변화에 따라 크게 변동될 수 있음이 나타났고, 따라서 BIRD의 경우, EX는 안정적이고 신뢰할 수 있는 지표로 사용된다.
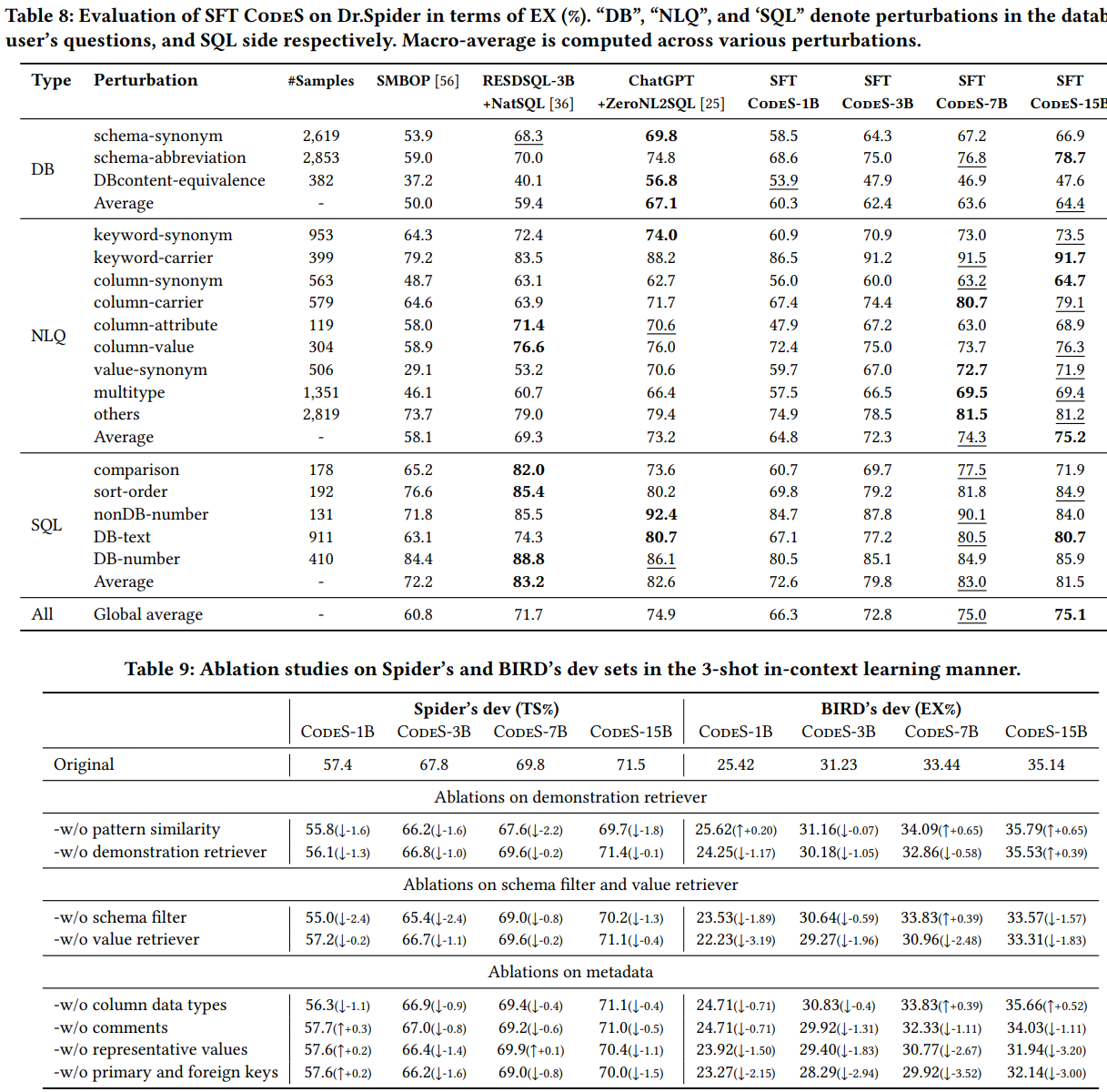
대부분의 경우 본인들의 CodeS가 좋았다고 실험 결에서는 보여준다.(bold체가 가장 좋은 것. 밑줄이 2번째로 좋은 것을 뜻함)


또한, Ablation study들을 시행하여 본인들의 방법론이 효과가 있음도 보였다.
그러나, 2024년 5월 28일 기준으로 현재는 10위로 밀려난 상태이다...




