
https://arxiv.org/abs/2211.01910
Large Language Models Are Human-Level Prompt Engineers
By conditioning on natural language instructions, large language models (LLMs) have displayed impressive capabilities as general-purpose computers. However, task performance depends significantly on the quality of the prompt used to steer the model, and mo
arxiv.org
Abstract.
LLM은 여러 방면으로 높은 성능을 보이지만, 모델을 조종하는데 사용되는 프롬프트의 quality에 따라 결과가 크게 좌우된다. 기존에는 사람이 직접 프롬프트를 작성하여 효과적으로 모델을 조종하였지만, 본 논문에서는 자동으로 프롬프트를 생성하는 APE 모델을 제안한다. APE 모델의 성능을 탐구함으로써 생성형 AI를 제어하고 조종하는 기반을 구축한다.
Introduction
- LLM (Large Language Model)
LLM이란 다양한 자연어 처리 작업을 수행할 수 있는 딥러닝 알고리즘을 의미한다.
방대한 Data set으로 훈련되고, 이를 통해 텍스트 또는 콘텐츠를 인식, 번역하고 예측, 생성할 수 있는 것이다.
생성형 AI의 한 유형으로 특히 텍스트에 대해 훈련되어 있는 모델이며, 매우 유연하게 사용되는 특징이 있다.
제공되는 프롬프트에 따라 문서를 요약하거나, 언어를 번역하는 등 완전히 다른 작업을 수행할 수 있다.
LLM을 우리가 원하는대로 활용하기 위해서는 여러가지 방법이 있는데, 그 중 하나가 적절한 프롬프트를 제공하는 프롬프트 엔지니어링 방식이다.
- PE (Prompt Engineering)
프롬프트란 생성형 AI 모델에 어떠한 작업을 수행하기 위해 전달하는 입력 메세지를 의미하며,
프롬프트 엔지니어링이란 프롬프트를 적절히 디자인하여 원하는 결과물을 도출할 수 있도록 안내하는 것을 의미한다.
자연어의 다양성을 유지하면서도 명확하게 프로그래밍이 가능한 특징이 있어
기존 사람의 자연어가 컴퓨터에게는 모호하고 부정확하여 발생하는 의사소통 과정의 한계,
LLM이 일반적으로 Auto-Regression 모델이기 때문에 단어의 순서에 따라 다르게 출력되는 답변 등을 보완할 수 있다.
- 문제 상황
하지만 프롬프트 엔지니어링에도 단점이 있다.
LLM 내부에서 어떤 동작이 이루어지는지 알 수 없기 때문에 각 모델에 잘 동작하는 프롬프트를 알 수 없고, 이로 인해 많은 테스트 과정이 필요했다.
기존에는 LLM에게 정확한 수행 결과를 요구하기 위해 '과제', '의도' 등을 사람이 직접 Input을 작성하는 방식으로 작업을 진행했지만, 원하는 결과를 성공적으로 얻기까지 많은 시간이 소요되었다.
이를 보완하기 위해 본 논문에서는 LLM을 주어진 지시사항에 따라 프로그램을 실행하는 일종의 '블랙 박스 컴퓨터'로 생각하고, 직접 많은 프롬프트를 테스트해 볼 필요 없이 LLM 스스로 효과적인 intruction을 생성, 선택하여 프롬프트 엔지니어링을 진행하는 알고리즘을 제안한다.
- APE (Automatic Prompt Engineer)

본 논문에서 제시하는 모델로, 자동으로 Instruction을 생성하고 선택하는 방법론이다.
(Instruction이란 모델이 수행하기 원하는 특정 명령어를 의미한다.)
- LLM으로 Instruction candidate set을 생성
- 계산된 score fuction을 기반으로 한 필터링을 거쳐 score가 가장 높은 최적의 Instruction 선정
- 이를 통해 프롬프트를 위한 다양한 후보군 생성 및 가장 적합한 명렁어 제공
본 APE로 제작한 Instruction은 기본적으로 다른 InstructionGPT나 사람이 직접 만든 Instruction보다 Zero-Shot performance에서 높은 성능을 보인다.
- Main Contribution
- LLM을 활용하여 자동으로 intruction 생성 및 선정
- 제안하는 APE 방법을 통해 Zero-shot에서 human-level performance를 달성하고, 24/24 Instruction Induction과 17/21 Big-Bench task를 달성
- APE의 다양한 측면을 탐구하는 정성적, 정량적 분석 제공 및 원하는 방향으로 LLM을 유도하는 APE 적용 사례 시연
Natural Language Program Synthesis Using LLMs
- Initial Proposal Distributions
LLM을 사용하여 Instruction을 무작위로 생성하고 제안하는 과정이다.
다음과 같이 여러 방법으로 프롬프트를 생성한다.



- Forward Mode Generation
Instruction이 문장 끝에 위치 - Reverse Mode Generation
Instruction이 텍스트 사이 아무데나 위치 - Customized Prompts
score function에 맞춰 변형하여 Instruction 전달
- Score Function
Data set과 생성한 Instruction 간의 유사도를 측정하는 과정
- Execution accuracy
모델에게 input으로 instruction과 질문이 주어졌을 때, 출력한 결과가 주어진 답변과 정확히 일치하는지 평가
정확히 일치하면 loss=1, 일치하지 않으면 loss=0
- Log probability
모델에게 input으로 instruction과 질문이 주어졌을 때, 정답 답변의 로그 확률
로그 확률로 표현함으로써 답변의 일치도를 더 정확히 평가
- Efficient score estimation
Training Data의 일부만을 사용하여 전체 Instruction 후보군에 대해 평가
High quality 후보군에 리소스를 많이 할당하고, Low quality 후보군을 필터링을 통해 리소스를 적게 할당
- 특정 기준 점수를 넘은 후보군은 따로 분류하여 새로운 Training Data로 평가
- 원하는 양의 후보군이 남을 때까지 반복
- 최종 후보군에서 전체 Training Data에 대한 점수를 계산해 가장 높은 Instruction을 선택
모든 후보군에 대해 평가하여 비용이 많이 드는 것을 방지
- Iterative Proposal Distributions
High score를 달성하는 후보군이 없는 경우, 좋은 Instruction set을 생성할 수 있도록 후보 집합을 다시 샘플링
Iterative Monte Carlo search 방법을 사용해 high score 후보군을 생성할 수 있도록 유도
성능에 큰 차이가 없기 때문에 선택적으로 사용
EXPERIMENTS
Large Language Models are Human-Level Prompt Engineers
- Instruction Induction
- LLM이 제공한 문제에 적합한 Instruction을 생성하는지 평가하기 위한 Task
- Task별 Training Data에서 5개의 Input, Output pair를 샘플링해 Best Instruction 선정
- InstructGPT를 통해 Instruction 평가

- Zero-Shot Learning
Zero-shot
모델이 학습 과정에서 배우지 않은 작업을 수행하는 것 (특정 예시를 제공하지 않음)
모델이 의미 정보를 제대로 학습하였는지를 확인하기 위한 용도로 사용
- 모든 Task에서 기존의 Greedy 알고리즘보다 APE가 높은 성능
- Human performance와는 비슷하거나 더 높은 성능
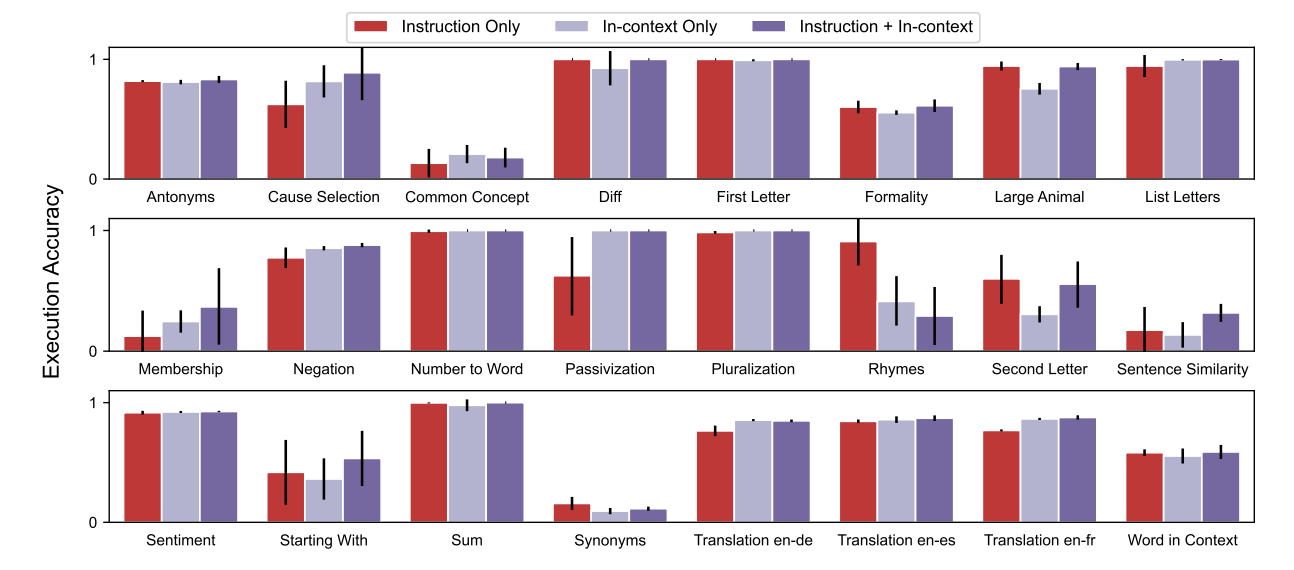
- Few-shot In-context Learning
Few-shot
모델이 적은 데이터도 잘 분류하는 것
특정 데이터를 구분하는 방법을 제대로 학습하였는지를 확인하기 위한 용도로 사용
- Zero-shot Execution Accuracy로 선정된 Instruction에 in-context를 추가해 성능 평가
- Instruction+in-context가 상당 부분에서 성능이 더 높음
- Few-shot Execution Accuracy로 선정한 Instruction의 경우 Rhymes를 제외하고 모두 성능 향상
- Big-Bench
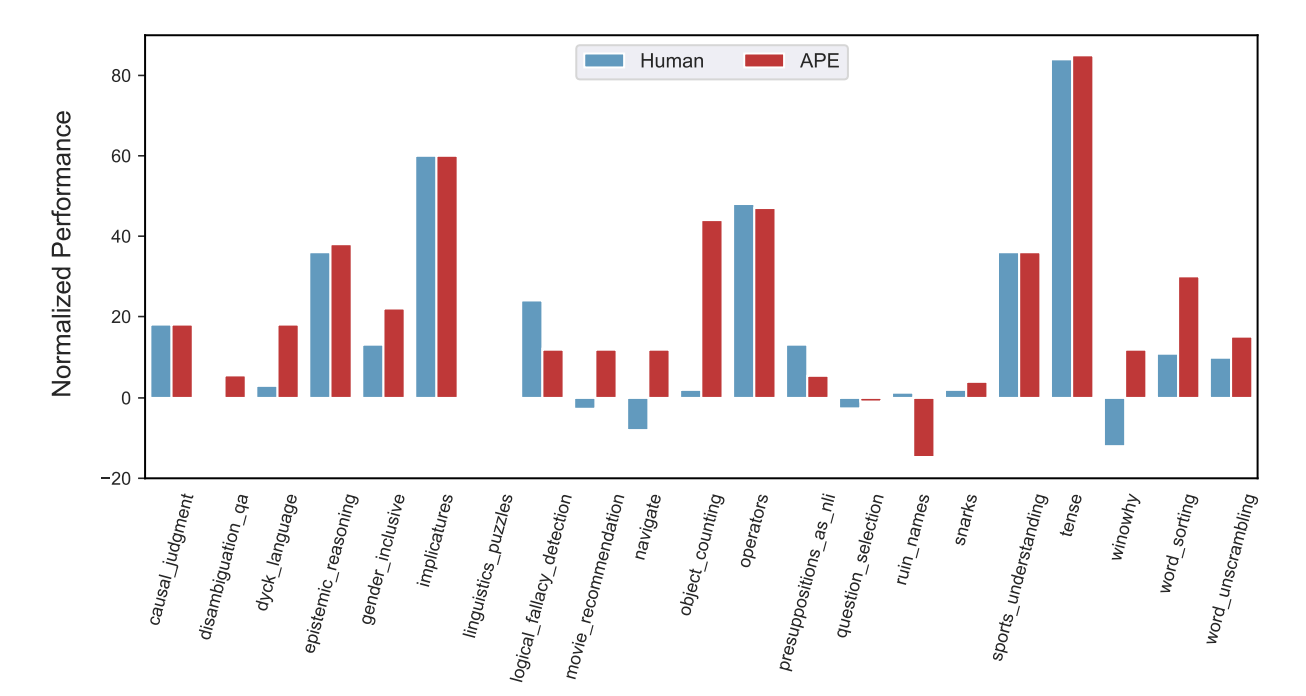
- Instruction Induction보다 더 어려운 task (Challenging task)에 대한 성능을 평가하기 위한 task
- Reverse mode generation으로 Instruction 후보군 생성 후 Execution accuracy로 선정
- 총 21개의 task 중 17개에 대해 human prompt 성능보다 높음
- Zero-shot Chain of Thought

Chain of Thought
언어모델이 최종 답변을 생성하는 과정에서 중간의 추론 단계를 설명하도록 만드는 프롬프트 방법
제공하는 task를 여러 단계의 subtask로 만들어 최종 답변을 생성
- APE로 제작한 CoT 프롬프트 : "Let's work this out in a step by step way to be sure we have the right answer."
- APE가 기존 프롬프트의 일부분을 최적화하도록 사용될 수 있는 가능성을 보임
- TruthfulQA

- 모델의 Truth response와 Informative response 생성 및 구분 능력을 평가하기 위한 Data set
- APE가 Truthfulness, Informativeness, both 세 가지를 최대화할 수 있는 Instruction 선정
- APE로 생성된 Instruction이 human engineered prompt보다 performance 높음
- APE로 생성된 Truthfulness + Informativeness Instruction이 Informativeness쪽으로 치우쳐 있음
Quaantitative Analysis
최적의 프롬프트를 생성하기 위해 효율적인 방식을 추가적으로 탐구
- LLMs for Proposal Distribution
- 모델의 크기와 initial proposal distribution quality
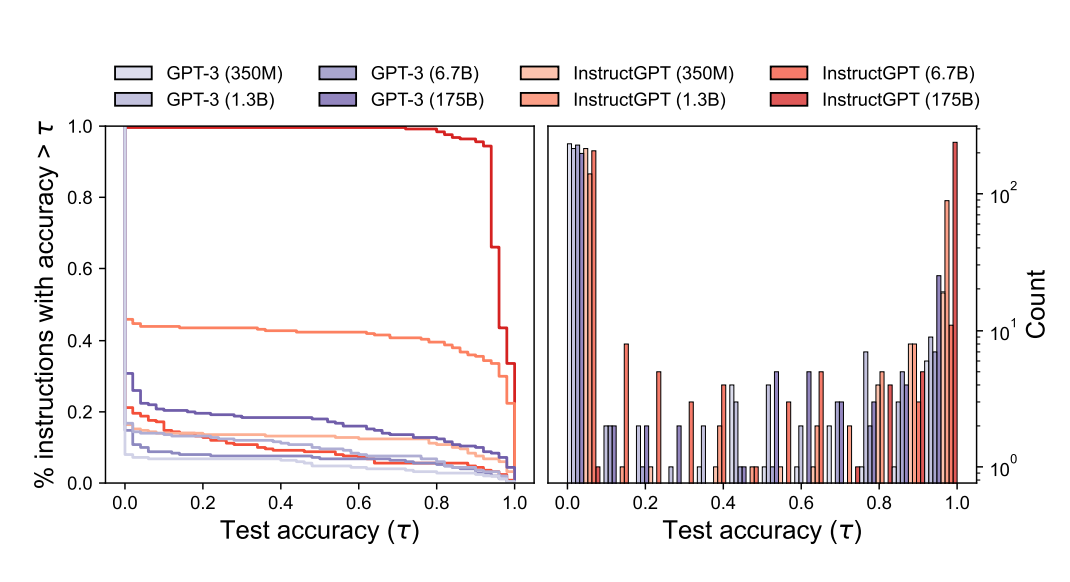
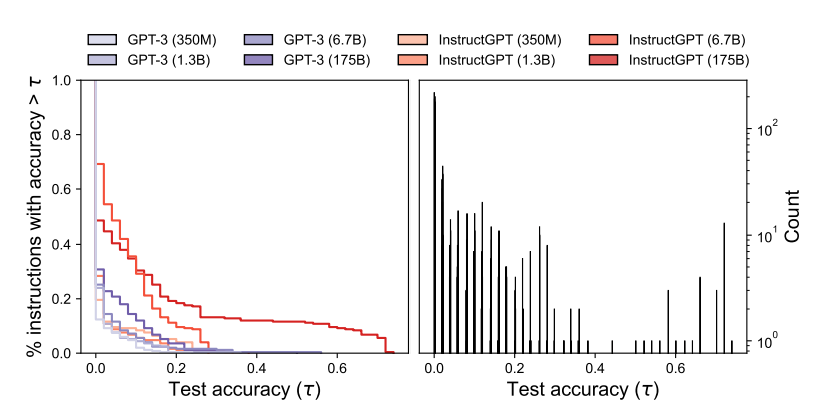
모델의 크기를 키우면 High quality의 proposal distribution을 진행하는 경향이 있다.
즉, 모델이 커지면 High quality Instruction 생성한다.
Simple task에서는 준수한 accuracy를 보이나, challenging task에서는 성능이 조금 낮아지는 것을 확인했다.
- LLMs for Selection
- Instruction 후보군 수와 High quality의 Instruction

Instruction 후보군의 양이 많을수록 (LLM에서 더 많은 Instruction을 샘플링 할수록) High quality Instruction을 생성한다.
샘플링 양 증가에 따라 Executition accuracy 증가, 64개에서 human-level 달성했다.
score function의 경우, Executition accuracy로 평가하는 것이 성능을 가장 잘 측정했다.
- Iterative Monte Carlo Search
- Iterative Search의 필요성

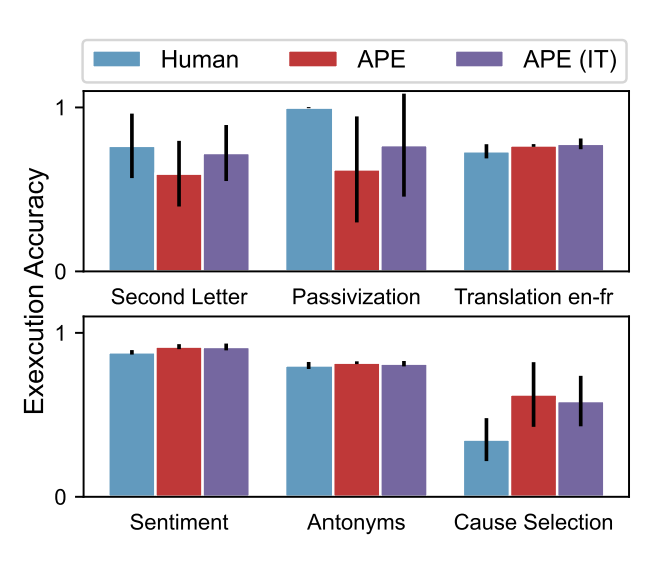
Iteration을 반복할수록 Instruction의 quality는 향상되었다. (반복 수가 증가함에 따라 향상되는 효과는 감소)
APE가 human performance에 비해 성능이 낮을 때는 Iteration 시 성능이 향상된다.
따라서 좋은 initial proposal 생성을 하지 못했을 때, Iteratice search가 도움이 된다.
Conclusion
- APE(Automatic Prompt Engineer) 방법론 제안
- Prompt Engineering의 자동화
- 생성된 Instruction을 통해 human resourse는 최소화, Performance는 다양한 task 분야에서 human-level 달성
'NLP' 카테고리의 다른 글
| [2024-1] 현시은 - Optimizing LLM Queries in Relational Workloads (0) | 2024.05.14 |
|---|---|
| [2024-1] 박태호 - Chain-of-Thought Reasoning Without Prompting (0) | 2024.05.11 |
| [2024-1] 김동한 - ResLoRA: Identity Residual Mapping in Low-Rank Adaption (1) | 2024.03.19 |
| [2024-1] 박태호 - Visual Question Answering (1) | 2024.03.19 |
| [2024-1] 염제원 - HAE-RAE Bench: Evaluation of Korean Knowledge in Language Models (0) | 2024.03.18 |



