[2025-1] 김학선 - DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
https://arxiv.org/abs/2501.12948
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrates remarkable reasonin
arxiv.org
Introduction
최근 사후 학습(Post-Training) 단계가 전체 훈련 파이프라인의 중요한 구성으로 떠오르고 있다.
Post-Training의 장점
- 추론 작업의 정확도 증가
- 사회적 가치와의 정합성
- 사용자 선호에 적응하는데 용이
- 사전 훈련과 비교했을 때 적은 계산 자원
이 논문에서는 SFT(Supervised Fine-Tuning) 없이 순수 RL(Reinforcement Learning) 프로세스로 모델이 자가 발전(self-evolution)하는 것이 목표이다. 이를 위해 DeepSeek-V3-Base 모델에 GRPO(Group, Relative Policy Optimization) 방식을 사용하여 RL을 진행한다. 추가적으로 위 RL 후 얻은 checkpoint에서 rejection sampling을 통해 SFT 데이터를 생성한다.
더 작은 밀집 모델로의 distillation(지식 증류)를 통해 더 큰 모델에서 발견된 추론 패턴으로 작은 모델들을 Fine-Tuning 하면 성능이 개선된다는 것을 볼 수 있다.
DeepSeek-R1-Zero: Reinforcement Learning on the Base Model
RL은 추론 작업에서 상당한 효과를 입증해왔으나, 데이터 수집에 많은 시간이 소요되는 SFT에 크게 의존했다. 하지만 이 논문에선 Supervised data 없이 LLM이 순수 RL 과정을 통해 스스로 진화하며 추론 능력을 개발할 가능성을 탐구한다.
Reinforcement Learning Algorithm
DeepSeek-V3-Base 모델에 사용했던 GRPO 방식은 그룹 상대 정책 최적화 방식으로 RL 훈련의 비용을 절감하기 채택했으며, 이 방법은 일반적으로 정책 모델과 동일한 크기를 가지는 비평가 모델(critic model)을 생략하고, 대신 그룹 점수(group scores)를 통해 기준(baseline)을 추정한다.
GRPO 방식에서는 각 질문 q에 대해 이전 정책으로부터 그룹 출력을 샘플링한 후 다음 목적 함수를 최대화하여 정책 모델을 최적화한다.
$$J_{GRPO}=\mathbb{E}[q\sim P(Q),\{o_i\}^G_{i=1}\sim\pi_{\theta_{old}}(o|q)]{1\over G}\sum_{i=1}^G\min({\pi_\theta(o_i|q)\over\pi_{\theta_{old}}(o_i|q)}A_i,\mathrm{clip}({\pi_\theta(o_i|q)\over\pi_{\theta_{old}}(o_i|q)},1-\epsilon,1+\epsilon)A_i)-\beta D_{KL}(\pi_\theta||\pi_{ref}))$$
- $\mathbb{E}[q\sim P(Q),\{o_i\}^G_{i=1}\sim\pi_{\theta_{old}}(o|q)]$: 정책 Q에서 샘플링된 q와 이전 정책($\pi_{\theta_{old}}$)에 의해 생성된 행동 그룹의 기대값
- ${\pi_\theta(o_i|q)\over\pi_{\theta_{old}}(o_i|q)}$: 새로운 정책이 이전 정책에 비해 $o_i$에 대해 얼마나 높은 확률을 부여하는지 나타낸다. 이 값에 이점 함수 $A_i$를 곱해서 보상 대비 개선 정도를 평가한다.
- 추가적으로 클리핑을 사용해서 정책의 안정적인 업데이트를 가능하게 만든다.
- $D_{KL}(\pi_\theta||\pi_{ref})$: 현재 정책 $\pi_\theta$가 참조 정책 $\pi_{ref}$에서 지나치게 벗어나지 않도록 규정한다.
- $A_i={r_i-\mathrm{mean}(\{r_1,r_2,\cdots,r_G\})\over \mathrm{std}(\{r_1,r_2,\cdots,r_G\})}$: $o_i$에서의 보상 $r_i$에 대한 정규화된 보상
Reward Modeling
DeepSeek-R1-Zero 모델을 훈련하기 위한 2가지 규칙 기반 보상 시스템
- Accuracy Reward: 응답이 올바른지 평가하는 보상
- Format Reward: 모델이 사고 과정을 <think></think> 태그안의 형태로 강제
DeepSeek-R1-Zero 모델 개발 과정에서 결과 기반 또는 과정 기반의 신경망 보상 모델은 사용하지 않는다.
why? 대규모 RL 과정에서 신경망 보상 모델이 보상 해킹에 취약하고, 보상 모델 재훈련이 추가적인 훈련 자원을 소모하며 전체 훈련 파이프라인을 복잡하게 만들 수 있다는 문제가 있기 때문이다.
Training Template
추론 과정(reasoning proccess)을 생성한 후 최종 답변(final answer)을 도출하도록 요구한다. 이러한 구조를 통해 반성적 추론(reflective reasoning)을 강제하여 특정 문제 해결 전략을 장려하며 모델의 자가 학습 과정을 확인할 수 있다.

Performance of DeepSeek-R1-Zero
Figure 2는 AIME 2024 벤치마크에서 DeepSeek-R1-Zero 모델이 RL 훈련 과정 동안 어떻게 발전했는지 보여준다. Figure 2에서 보이듯 RL이 진행됨에 따라 성능이 꾸준하고 일관되게 향상되는 것을 볼 수 있고, 이를 통해 RL 만으로도 추론 능력을 획득할 수 있다는 것을 알 수 있다.
추가적으로 DeepSeek-R1-Zero는 다수결 투표를 통해 성능을 더욱 향상시킬 수 있다.
- pass@1: 모델의 하나의 답변이 정답을 맞출 확률
- conv@16: 모델의 16개의 답변의 다수결 응답으로 정답을 맞출 확률

Table 2는 DeepSeek-R1-Zero 모델과 OpenAI-o1-0912 모델을 다양한 추론 관련 벤치마크에서 비교 분석한 표이다. Table 2를 통해 DeepSeek-R1-Zero가 특정 벤치마크에서는 다수결 투표 여부와 관계없이 경쟁력 있는 성능을 달성했고, 추론 작업에서의 추가적인 발전 가능성을 시사하였다.

Self-evolution Process of DeepSeek-R1-Zero
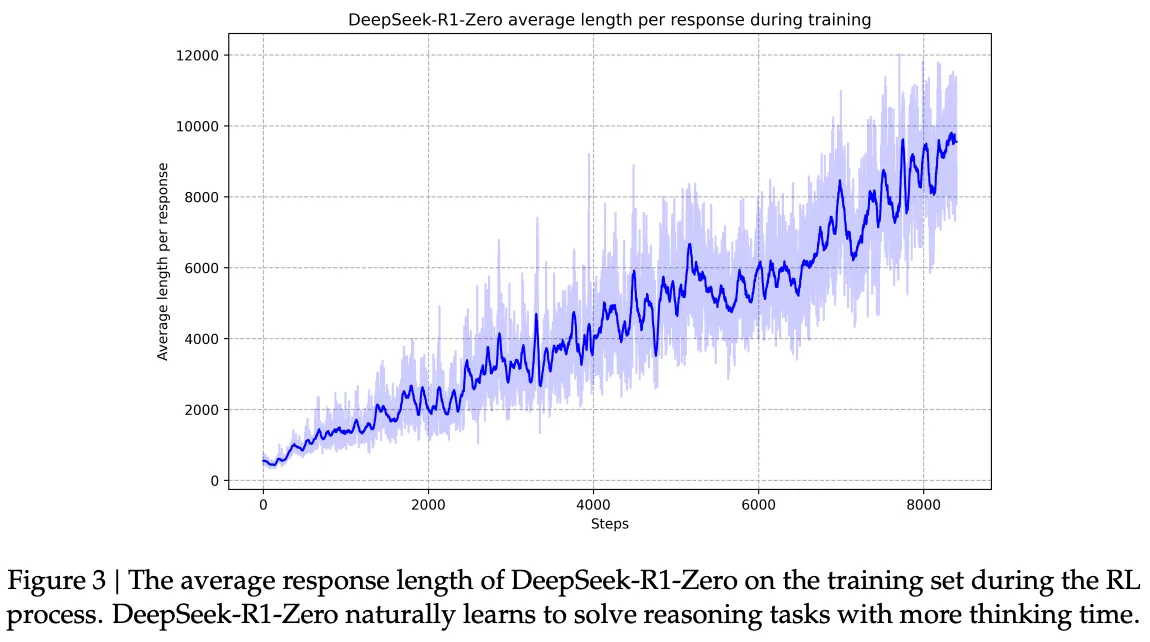
Figure 3를 보면 DeepSeek-R1-Zero의 사고 시간은 훈련 과정동안 지속적으로 개선되는 모습을 보여준다. DeepSeek-R1-Zero는 확장된 시험 시간을 활용하여 점차 복잡한 추론 작업을 해결하는 능력을 자연스럽게 획득한다. 이를 통해 수백 수천의 토큰을 생성하고 더 깊은 사고과정을 탐색하고 다듬을 수 있다.
이러한 자발적인 발전은 추론 능력을 크게 발전시켜, 모델이 더 도전적인 작업을 더 효율적이고 정확하게 해결할 수 있게 한다.
Aha-moment of DeepSeek-R1-Zero
Table 3를 보면 aha-moment는 모델의 중간 버전에서 발생한다. 이 aha-moment에서 모델은 문제에 더 많은 사고 시간을 할당하고, 초기 접근 방식을 재평가하는 방법을 배운다. 이를 통해 문제에 대한 적절한 유인책만 제공하면, 모델이 스스로 고급 문제 해결 전략을 개발한다는 사실을 보여준다.

Drawback of DeepSeek-R1-Zero
이렇게 대규모 RL을 통해 학습한 DeepSeek-R1-Zero에는 읽기 어려움과 언어 혼합의 문제가 있다. 이를 해결하기 위해 Cold-start data를 이용한 강화 학습 방법을 탐구했다.
DeepSeek-R1: RL with Cold Start
DeepSeek-R1-Zero 모델에서 나온 질문
- 소량의 고품질 데이터를 초기 입력으로 활용하여 추론 성능을 더욱 향상시키거나 수렴 속도를 가속화할 수 있는가?
- 명확하고 일관된 CoT(Chain of Thought) 생성 뿐 아니라 강력한 일반화 능력을 보여주는 사용자 친환경적인 모델을 어떻게 훈련할 수 있는가?
1. Cold Start
기본 모델의 RL 훈련 초기 불안정한 cold start 단계의 방지를 위해 소량의 긴 CoT 데이터를 수집하여 모델을 Fine-Tuning 한다.
데이터 수집 방법
- 긴 CoT를 예시로 사용하는 few-shot prompt 기법
- 모델 반영 및 검증을 포함하여 상세한 답변 생성 요청
- DeepSeek-R1-Zero의 출력물을 읽기 쉬운 형식으로 수집
- 인간 주석자를 통해 후처리하여 결과를 정제
위 방법으로 수집된 cold-start 데이터의 이점은 다음과 같다.
Cold Start 데이터의 이점
- 가독성: cold-start 데이터를 생성 시 응답 끝에 요약을 포함하는 가독성 있는 패턴을 설계하고, 사용자 친화적이지 않은 응답은 필터링 한다.
출력 방식: |special token|<reasoning_process>|special token|<summary>
- reasoning_process: 쿼리에 대한 CoT
- summary: 사고 결과 요약
- 잠재력: 인간의 사전 지식을 반영하여 데이터 패턴을 설계하여 성능을 높인다.
2. Reasoning-oriented RL(추론 중심 RL)
DeepSeek-V3-Base를 Cold Start 데이터로 Fine-Tuning 후, 대규모 RL 학습 프로세스를 적용하며, 이때는 모델의 추론 능력 향상에 중점을 둔다. RL 훈련 중 언어 혼합 문제의 완화를 위해 언어 일관성 보상(Language Consistency Reward)을 도입한다. 여기서 언어 일관성 보상은 CoT 방식에서 목표 언어 단어가 전체 답변에서 차지하는 비율에 기반해 결정되는 보상이다.
비록 제거(ablation) 실험 결과에서는 이러한 조정이 모델 성능의 약간의 저하를 초래하는 것으로 나타났지만, 인간의 선호도에 맞춰서 가독성을 개선하는데 기여했다.
최종적으로 추론 작업의 정확도와 언어 일관성 보상을 직접 합산하여 최종 보상을 형성한다.
3. Rejection Sampling and SFT
추론 중심 RL에 수렴하면, 그 결과 Checkpoint를 활용하여 다음 단계의 SFT 데이터를 수집한다. 이러한 데이터는 다음과 같은 방식으로 생성한다.
- Reasoning Data
추론 프롬프트를 큐레이션하고 이전 RL 훈련에서의 checkpoint를 활용하여 rejection sampling을 통해 추론 경로를 생성하여 새로운 데이터를 추가한다. 일부 데이터를 DeepSeek-V3 모델에 정답과 모델 예측 값을 입력해 판단하는 생성 보상 모델을 활용한다.
이때, 혼합 언어, 긴 문단, 코드 블럭이 포함된 CoT는 필터링한다.
각 프롬프트에 대해 여러 응답 샘플링을 진행하며 올바른 응답만을 유지하여 약 60만 개의 추론 관련 훈련 샘플을 수집한다. - None-Reasoning Data
DeepSeek-V3 파이프라인을 채택하고, DeepSeek-V3의 SFT 데이터셋의 일부를 사용한다.
특정 비추론 작업에선 프롬프트를 통해를 통해 질문에 답하기 전 DeepSeek-V3을 호출하여 잠재적으로 CoT를 생성한다.
이를 통해 약 20만 개의 비추론 관련 훈련 샘플을 수집한다.
→ 총 약 80만 개의 샘플로 구성된 큐레이션된 데이터를 활용해 DeepSeek-V3-Base를 2 epoch 동안 Fine-Tuning 했다.
4. RL for all Scenarios
인간의 선호도에 맞추기 위해 2차 RL 도입하여 모델의 Helpfulness와 Harmlessness를 개선하며 추론 능력을 더욱 정제했다.
- 추론 데이터: 규칙 기반 보상을 활용하여 학습을 유도
- 일반 데이터: 인간 선호도를 반영하기 위해 보상 모델을 사용
DeepSeek-V3 파이프라인 기반으로 동일한 선호 쌍 및 훈련 프롬프트 분포를 채택한다.
- Helpfulness: 최종 요약에 집중, 사용자에게 응답의 유용성과 적절성이 강조되도록 평가
- Harmlessness: 모델의 전체 응답을 평가, 생성 과정에서 발생할 수 있는 위험, 편향, 유해 컨텐츠를 식별하고 완화한다.
→ 이를 통해 추론 능력에서 뛰어나면서도 유용하고 무해한 모델 훈련 성공했다.
Distillation: Empower Small Models with Reasoning Capability
Qwen2.5-Math(1.5B, 7B, 14B, 32B)과 Llama(3.1-8B, 3.3-70B-Instruct)와 같은 오픈 소스 모델을 대상으로 DeepSeek-R1에서 큐레이션한 80만 개의 샘플을 활용해 직접 Fine-Tuning한 결과 단순 지식 정제 방법이 더 작은 모델의 추론 능력을 상당히 향상시킨다는 것을 확인했다. 이때, 증류 모델에는 RL 단계를 포함하지 않고, SFT만을 적용했다.
Experiment
DeepSeek-R1 Evaluation
아래 Table 4는 DeepSeek-R1 모델과 다른 모델들과의 성능을 비교한 표이다. 이를 통해 DeepSeek-R1은 Code Benchmark를 제외한 나머지 벤치마크 중 수학과 중국어 부분에서 높은 성능을 보이고 영어 부분에서는 OpenAI o1-1217과 비슷하거나 OpenAI o1-1217보다 높은 성능을 보인다.

Distilled Model Evaluation
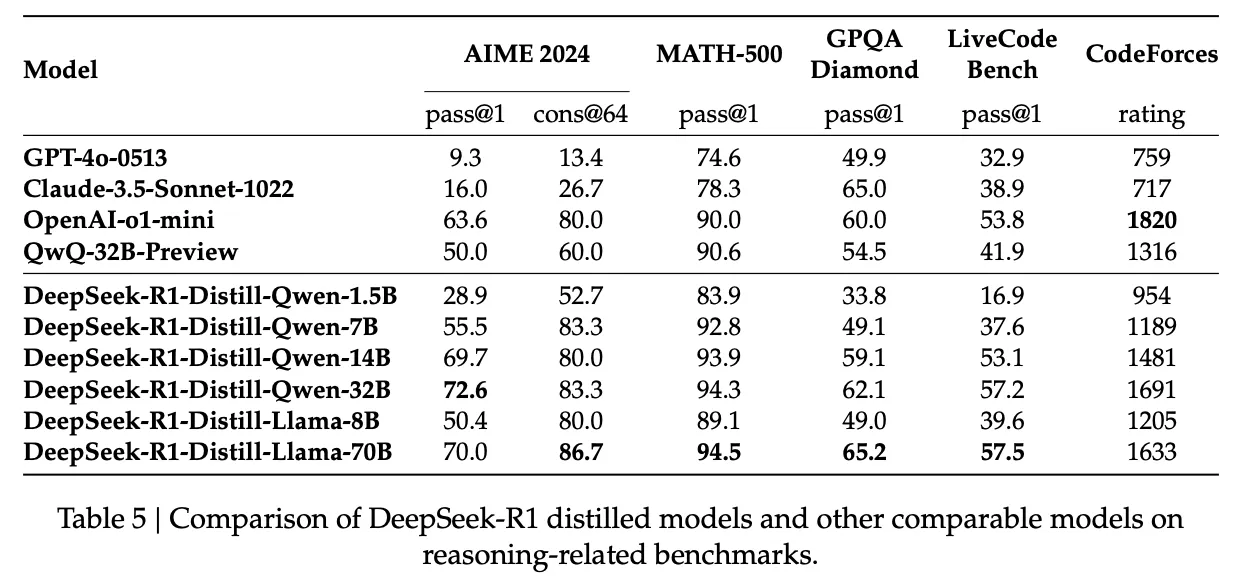
아래 Table 5는 단순 DeepSeek-R1의 출력을 증류하는 것만으로도 효율적인 DeepSeek-R1-7B 모델이 GPQA Diamond를 제외한 모든 측면에서 GPT-4o-0513을 능가하는 성능을 보인다. DeepSeek-R1-70B에서는 CodeForces를 제외한 대부분의 벤치마크에서 OpenAi-o1-mini를 크게 상회했다. 이를 통해 증류 기법의 강력한 가능성을 입증했고, 증류된 모델에 강화 학습을 적용할 경우 상당한 추가 성능의 향상이 발생함을 확인했다.
Discussion
Distillation v.s. RL
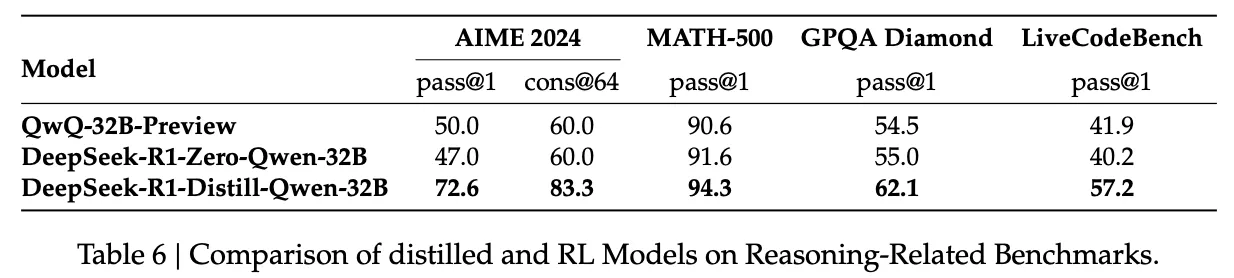
증류 없이도 대규모 RL 훈련을 통해 유사한 성능을 달성할 수 있는가에 답하기 위해, Qwen-32B-Base 모델을 대상으로 수학, 코드, STEM 데이터를 활용한 대규모 RL을 총 10,000 진행하여 훈련을 통해 DeepSeek-R1-Zero-Qwen-32B를 개발했다. Table 6에 제시된 실험 결과에 따르면, DeepSeek-R1-Distill-Qwen-32는 모든 벤치마크에서 DeepSeek-R1-Zero-Qwen-32B를 크게 능가하는 성능을 보였다.
- 증류의 우수성
→ 강력한 모델을 소형 모델에 증류하는 방식은 탁월한 성과를 가져온다. 반면, 소형 모델이 대규모 RL 훈련에 의존할 경우 막대한 계산 자원이 필요하며 증류 성능에 미치지 못할 가능성이 높다. - 강력한 베이스 모델과 대규모 RL 필요성
→ 지능의 경계를 넘어서기 위해서는 더 강력한 베이스 모델과 대규모 RL 훈련이 여전히 필요하다.
Conclusion
- DeepSeek-R1-Zero는 초기 데이터에 의존하지 않는 순수 RL 접근 방식으로, 다양한 작업에서 높은 성능을 달성했다.
- DeepSeek-R1은 초기 데이터를 활용하고 반복적인 RL FT를 통해 더 강력한 성능을 발휘하며, 여러 작업에서 OpenAI-o1-1217과 비슷한 성능을 기록했다.
- 추론 능력을 소형 밀집 모델로 증류하는 가능성을 탐색하기위해, DeepSeek-R1을 사용하여 생성한 학습 샘플로 여러 소형 밀집 모델을 FT한 결과 성능이 크게 증가하는 인상적인 성과를 보였다.