
https://arxiv.org/pdf/1610.02136

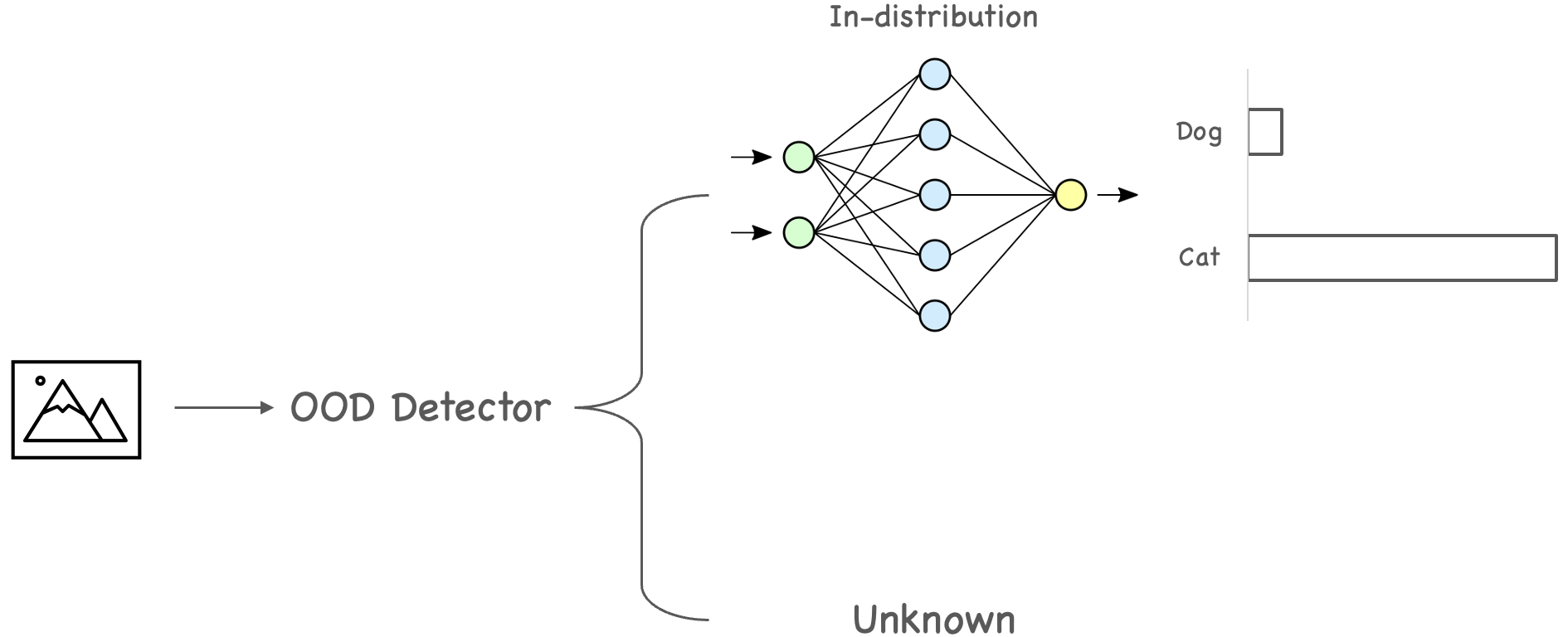
- Image Classification에 학습 시 한번도 보지 못한 데이터 분포에 대해서도 높은 신뢰도를 갖고 잘못된 예측을 할 수 있다.
- 이처럼 모델의 학습 과정에서 고려되지 않는 데이터셋을 Out-of-Distribution이라고 하며 해당 논문은 OOD Detection하는 task를 처음으로 제시한 논문이다.
- OOD detection에 대해 문제 정의와 평가 방법 등을 제시하였다.
Abstract
- $\mathrm{Softmax}$ 의 Maximum을 confidence score를 임계값으로 사용하여 컴퓨터 비전, 자연처 처리, 자동 음성 인식 분야에서의 평가 방법을 제시하였다.
- OOD Detection의 후속 연구에 대한 baseline 모델을 제시하였다.
1. Introduction
- OOD는 현실에서 위험한 결과를 야기할 수 있다.
- 예를 들어 딥러닝을 활용 의료 진단 과정에서 학습하지 않은 유형이라 판단하여 정상이라고 판단할 수 있다.
- MNIST image에 random Gaussian nosie를 주입한 실험을 통해 $\mathrm{Softmax}$ distribution의 prediction probabiltiy가 confidence와 직접 일치하지 않음을 확인했다.
- Examaple이 잘못 분류가 되었는지 아니면 학습 데이터와 다른 distribution에서 나온 건지 결정하는 방법을 제공한다.
2. Problem formulation and evaluation
- 본 연구는 1. error와 success prediction 2. In-distribution과 Out-of- distribution detection 문제에 관심을 두고 있다.
- error & success prediction : test에서 example을 정확하게 분류하는지 예측할 수 있는지
- In-distribution & Out-of-distribution detection : test example이 traning data와 다른 distribution에서 나온 것인지 예측할 수 있는지
- 위 문제를 Threshhold 값과 무관한 두 가지 평가 지표인 AUROC와 AUPR로 다뤘다.

- AUROC
- FPR과 TPR을 축으로 그린 ROC 그래프 아래의 넓이
- AUROC는 positive example이 negative example 보다 더 큰 확률로 해석될 수 있어 데이터 불균형에 영향을 받는다.
- AUPR
- Recall과 Precision을 축으로 그린 PR 그래프 아래의 넓이
- AUROC를 보완하기 위해 AUPR도 평가 지표로 같이 쓰인다.
3. Softmax prediction probability as a baseline
$$ \mathrm{Softmax}{(x_i)}=\frac{\exp(x_i)}{\sum_j{\exp(x_i)}} $$

- Softmax는 multi-class classification의 출력층에서 사용되는 활성화 함수이다.
- $e^x$로 인해 작은 값의 차이도 크게 구분할 수 있는데 이 때문에 잘못된 분류를 야기하게 된다.
- 출력이 근소한 차이임에도 Softmax를 통과하게 되면 크게 벌어지게 된다.

- Out-of-distribution이 Softmax 확률값이 비교적 낮은 것을 볼 수 있다.
- Maximum Sofrmax Probability에 대한 Threshold 적용
- Softmax 확률값 중 Maximum을 Threshold와 비교하여 Threshold보다 높으면 In-distribution이라 판단하여 classification을 진행하고 낮으면 Out-of-distribution이라고 판단하여 학습 데이터 내에 데이터가 없다고 판단한다.
3.1 Computer Vision
- 컴퓨티 비전 분야 실험은 MNIST, CIFAR-10, CIFAR-100 등의 데이터셋을 사용하여 성능을 평가하였다.
- Base와 비교하여 성능이 높은 것을 볼 수 있다.
- Base 같은 경우는 Random Classifier의 결과로 AUROC에서 Random일때 0.5인 것을 생각하면 된다.
- ‘Succ’은 correctly classified examples을 positive class로 취급한다.
- ‘Err’는 incorrectly classified example을 positive class로 취급한다.
- ‘Pred’는 이상값에 대한 maximum probabilty를 mean한 것이며 낮을 수록 이상값을 판단하기 쉽다.

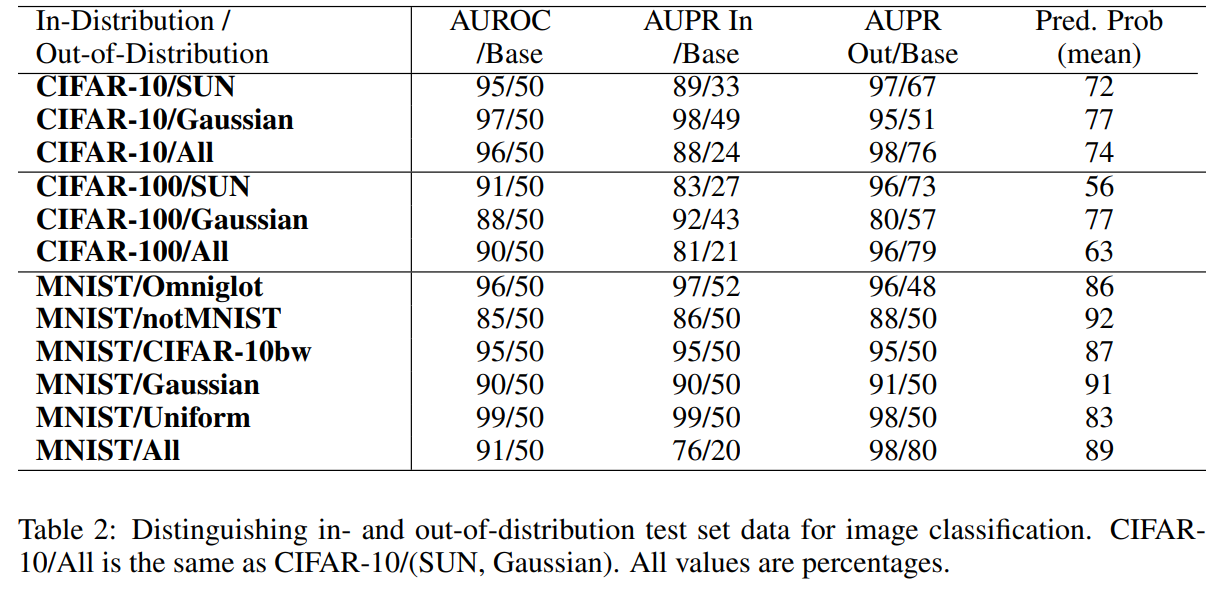
- Gaussian은 Gaussian noise를 추가한 것이 아닌 완전한 noise 이미지로 out-of-distribution 이미지이다.
- SUN은 Scene Understanding으로 해당 데이터 셋도 Out-of-distribution 데이터셋이다.
- Table 2는 In-Distribution과 Out-of-Distribution을 테스트 데이터로 둬 성능을 평가한 결과이다.
- ‘In’은 in-distribution, correctly classified examples을 positivie으로 하고 predicted class에 대한 $\mathrm{Softmax}$probability를 metric으로 한다.
- ‘Out’은 out-of-distribution examples을 positive로 하고 probability의 negative를 사용한다.
3.2 Natural language processing
- NLP 분야에서의 다양한 task에서도 성능을 평가하였다.
3.2.1 NLP - Sentiment classification
- IMDB 데이터셋을 사용하여 영화 리뷰와 고객 리뷰 이진 감정 분류 성능을 평가하였다.

- correctly와 incorrectly 분류 example 간 차이가 있음을 알 수 있다.

3.2.2 NLP - Text categorization
- 뉴스 그룹과 Reuters 뉴스 데이터셋의 주제를 분류하는 성능을 평가하였다.
- 뉴스 그룹 데이터에는 2만개의 문서가 포함된 20개의 서로 다른 주제가 있다.
- Reuters 52 데이터셋에는 52개의 뉴스 주제와 9천개가 넘는 뉴스 기사가 있다.

- 20개 뉴스그룹에서 5개 뉴스그룹 주제, Reuters 8에서 2개 뉴스 주제, Reuters 52에서 12개 뉴스 주제를 제외하고 학습했다.
- Table 5에서 해당 오류를 감지하는 것을 알 수 있다.

- Table 6에서도 분포를 벗어난 대상을 감지할 수 있음을 알 수 있다.
3.2.3 NLP - Part-of-speech tagging
- Wall Street Journal과 Twitter 데이터를 사용하여 텍스트의 품사를 tagging하고 분류하는 성능을 평가하였다.


- Weblog 데이터는 Twitter보다 더 WSJ에 가깝기 때문에 OOD detection이 어렵다.
- Weblog보다 Twitter에서 나온 단어의 경우 더 쉽게 detection을 할 수 있음을 알 수 있다.
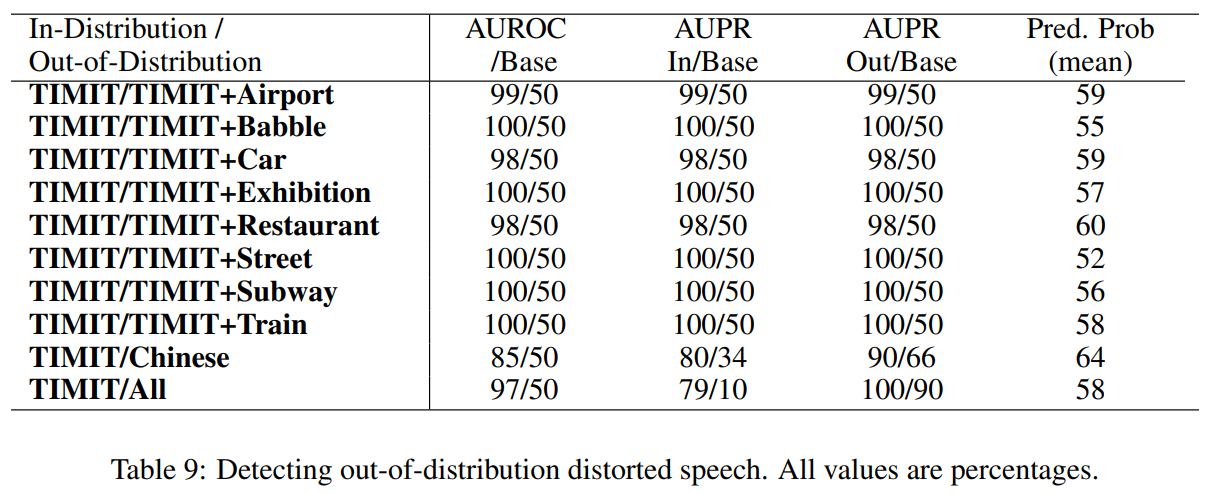
3.3 Automatic speech recognition
- TIMIT 오디오와 Aurora-2 데이터셋을 사용하여 음성 인식에서도 성능을 평가하였다.
- 실제 소음과 중국어 음성 말뭉치 THCHS-30 데이터셋을 테스트로 사용하였다.
4. Abnormality detection with auxiliary decoders
- $\mathrm{Softmax}$ 임계값에 더해 보조 디코더(auxiliary decoder)를 사용하여 데이터를 더 감지할 수 있도록 했다.
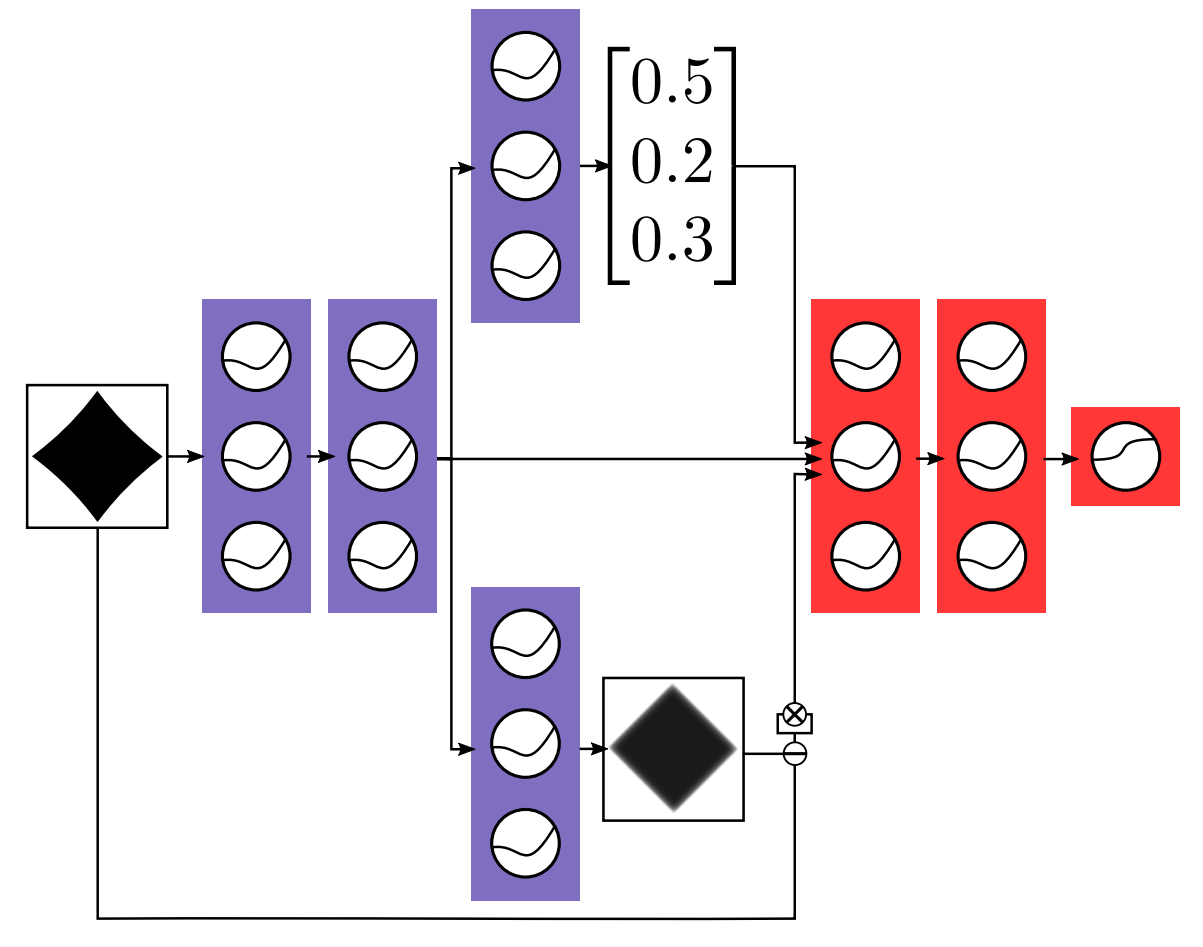
- 위의 normal classifier와 아래의 입력을 재구성하는 보조 디코더(auxiliary decoder)를 학습한다.
- 보라색 레이어를 고정시키고 in-distribution data로 먼저 학습시킨다.
- Out-of distribution data와 In-distribution data를 빨간색 레이어를 통해 학습시켜 해당 data가 OOD이면 0, in-distribution이면 1로 분류하는 task를 수행한다.
- 결과적으로 noise는 abnoramly class에 clean은 normal class에 속하게 되었다.
4.1 TIMIT
- TIMIT 데이터셋을 사용
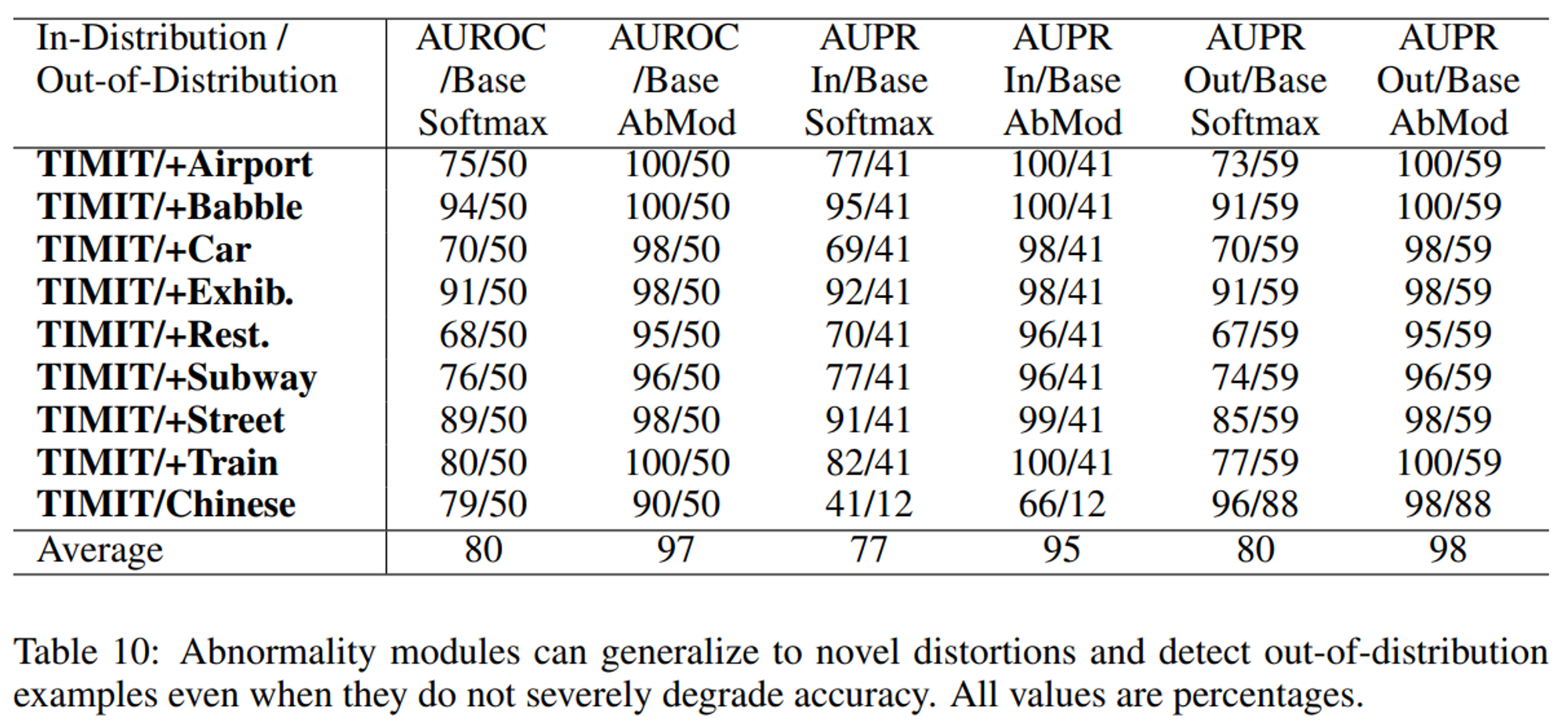
- abnormality module을 사용하는 것이 정확도를 심각하게 저하시키지 않더라도 분포를 벗어난 examples을 잘 감지하는 것을 볼 수 있다.
4.2 MNIST
- MNIST 데이터셋을 사용

- MNIST에서는 향상된 것을 볼 수 있다.
5. Discussion and future work
- abnormality module을 제시하였다.
- intra-class variance를 활용하여 똑같이 예측된 class에서 example 사이의 거리고 abnormally high하다면 OOD라고 할 수 있다.
- RNN도 OOD에 대한 example에 대해 abnormal을 판단할 수 있다.
- detection에 대해 known-unknwon인지 unknown-unknown인지 세분화(fine-grained) 할 수 있다.
6. Conclusion
- 다양한 아키텍처와 데이터셋에서 detection을 위한 $\mathrm{Softmax}$ prediction probability baseline을 제시하였다.
- abnormality module을 제시하여 향후 연구 가능성을 보였다.
[참고]
https://blog.munhou.com/2022/12/01/DetectingOut-of-Distribution Samples with Knn/



